ECCV2024 Oral | 第一视角下的动作图像生成,Meta等提出LEGO模型
AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
本文的作者主要来自于 Meta 和佐治亚理工大学。第一作者是佐治亚理工机器学习专业的博士生赖柏霖(目前也是 UIUC 的访问学生),导师为 James Rehg 教授(已转入 UIUC),主要研究方向是多模态学习,生成模型和视频理解,并在 CVPR、ECCV、BMVC、ACL 等会议发表相关论文,参与 Meta 主导的 EgoExo4D 项目,本文工作是赖柏霖在 Meta 的 GenAI 部门实习时完成,其余作者均为 Meta 的研究科学家。
作者主页:https://bolinlai.github.io/
当人们在日常生活和工作中需要完成一项自己不熟悉的任务,或者习得一项新技能的时候,如何能快速学习,实现技能迁移(skill transfer)成为一个难点。曾经人们最依赖的工具是搜索引擎,用户需要自己从大量的搜索结果中筛选出答案。最近几年出现的大语言模型(LLM)可以依据用户的问题归纳生成答案,极大地提升了回复的准确率和针对性 (如图 1 所示),然而大语言模型生成的回复通常非常繁琐冗长,而且包含诸多笼统的描述,并没有针对特定用户当下的环境进行定制化的回应。

随着大语言模型逐渐获得理解图片的能力,一个简单直接的解决方案是用户在提出问题的同时也提供一张包含眼前场景的照片,这样模型便可以根据用户当下的环境来生成更准确直接的指令,从而让人们更容易跟随指令完成任务。那是否有比这更简单直接的方法呢?之前的神经科学研究表明,人类大脑处理图片的速度要远快于处理文字,如果模型可以直接生成一张图片来给用户展示如何执行下一步,便可以进一步提升人们的学习效率。
在今年的 ECCV Oral Session,来自 Meta、佐治亚理工(Georgia Tech)和伊利诺伊香槟分校(UIUC)的研究者们提出一个新的研究问题:如何基于用户的问题和当前场景的照片,生成同一场景下的第一视角的动作图像,从而更准确地指导用户执行下一步行动?

论文地址:https://arxiv.org/pdf/2312.03849
项目主页:https://bolinlai.github.io/Lego_EgoActGen/
开源代码:https://github.com/BolinLai/LEGO
挑战和解决方案
目前有众多大模型在图片生成任务上取得了极佳的效果,但这些模型在应用到本文提出的动作图像生成的问题时,有两个尚未解决的挑战(如图 2 所示):(1)当下的数据集中的动作标注非常简略(通常为动词 + 名词),这使得模型难以理解动作的细节;(2)现存模型的预训练数据基本上都是第三视角的物体或者场景图片,并且文本中鲜有动作相关的描述,这与本文任务中所使用的数据之间存在很明显的差距(domain gap)。

针对这两个问题,研究者们提出使用第一视角的动作数据对大语言模型进行微调(visual instruction tuning)来丰富动作的具体细节,同时将大语言模型的图像和文本特征作为扩散模型的额外输入,从而缩小 domain gap。
基于 GPT 的数据收集
为了对大语言模型进行训练,本文使用 GPT-3.5 来收集详细的动作描述作为训练数据(见图 3),具体方法为对于少量数据(本文中为 12 个动作)进行人工扩写动作细节,然后将这些人工撰写的描述放入 GPT 的输入(prompt)中进行基于上下文的学习(in-context learning),同时本文作者还将物体和手部的包围框(bounding box)一起输入,从而使 GPT 可以理解当前环境下物体与手的空间位置信息,通过这种方案,GPT 可以模仿少量人工标注的数据来生成大量的动作描述,这些采集到的数据会被用于大语言模型的微调。

模型结构和方法

本文提出的 LEGO 模型分为两个步骤:(1)大语言模型基于视觉指令的微调(visual instruction tuning),(2)动作图像生成(action frame generation)。
基于视觉指令的微调(如图 4a 所示):本文将用户提供的包含当前环境信息的图片输入预训练好的图片编码器,然后使用一层线性层将特征映射到 LLM 的特征空间,与用户的问题一起输入 LLM 中,LLM 可以基于图片信息来生成可以直接应用于当前环境的详细动作指令,从而为动作图像生成提供更多的细节,解决了现有数据集中动作标注过于简略的问题。
动作图像生成(如图 4b 所示):本文使用隐空间扩散模型(latent diffusion model)来进行图像生成,考虑到本文数据和现有模型预训练数据之间的差异,作者将大语言模型中的图像特征以及文本特征一起作为额外的条件(condition),和动作描述一起输入到扩散模型中。为了连接大语言模型和扩散模型的特征空间,作者使用了线性层来映射图片特征;对于文本特征,本文在线性层之外使用了两层自注意力(self-attention)层来获得文本整体的语义;对于动作描述,则直接使用预训练的文本编码器进行特征提取。
对比及消融实验
本方法在两个大型第一视角动作数据集 -- Ego4D 和 Epic-Kitchens 上进行验证,研究者们定义了每个动作开始和正在进行时的关键帧,并且过滤掉部分低质量的数据。

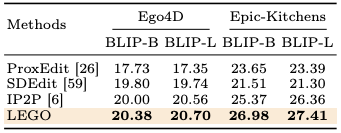

实验中,作者将提出的方法与多个图生成模型在多个指标下进行对比,除此之外还用人工评测的方式进一步巩固实验结果。可以看到,在图像对图像(image-to-image)的六个指标中,LEGO 在两个数据集上基本都超过了对比的模型,即使在 Epic-Kitchens 的 FID 指标中略低于 IP2P,但依然是第二好的效果。除此之外,本文还使用图像对文本(image-to-text)的指标来评测生成的图片是否正确体现了动作描述,从结果可以看到,LEGO 依然在两个数据集上获得最好效果。在人工评测(user study)中,研究者们将四个模型生成的图片打乱顺序让用户选择生成质量最高的图片,结果表明,超过 60% 的用户认为 LEGO 生成的图片最符合他们的需求。

本文还对提出的模型进行了消融实验,结果表明详细的动作描述、LLM 的图片和文字特征均可以提升生成图片的质量,其中图片特征对于性能的提升最为明显。
可视化成果展示

从生成图片的效果(图 6)可以看出,LEGO 模型能够很好地理解用户提问的动作细节,并生成准确的动作图像,除此之外,生成图片很好地保留了原图的背景信息,从而用户可以更简单直接地遵循图片指导来完成每一步动作。

研究者们还成功验证了 LEGO 可以在同一场景下生成多种动作图像(包括未训练过的动作),从而说明 LEGO 可以泛化到更广泛的场景。
总结
1. 本文提出了一个全新的问题:第一视角下的动作图像生成,从而可以提升人们学习新技能的效率。
2. 本文创新性地提出了对大语言模型进行微调来丰富动作细节,同时使用大语言模型的特征来提升扩散模型生成图像的性能。
3. 本文提出的 LEGO 模型在两个大型数据集和多个指标上均取得目前最好的效果。
