【Open AI o1 实现原理】在推理测试时优化LLM的计算比扩大模型参数更有效 Scaling LLM Test-Time Compute
光剑书架上的书 2024-10-02 10:31:02 阅读 80
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
全文摘要
本篇论文主要探讨了如何在自然语言处理中通过增加测试时间计算量来提高模型性能的问题。作者分析了两种主要机制:搜索密集、基于过程验证器奖励模型以及根据提示自适应更新模型响应分布。他们发现不同的方法对于不同难度的提示效果差异很大,并提出了“计算最优”的策略以最有效地分配测试时间计算量。实验结果表明,在匹配FLOPS的情况下,使用测试时间计算可以超过一个14倍更大的模型。这项研究为构建能够自主改进并操作开放性自然语言的一般自我改进代理提供了关键步骤。
论文速读
论文方法
方法描述
该论文提出了一个统一的观点来使用测试时间计算,并分析了一些代表性方法。作者将使用额外的测试时间计算视为在给定提示下修改模型预测分布的方式。理想情况下,测试时间计算应该比仅仅使用预训练的语言模型(LLM)更好地生成输出。总的来说,有两种方式可以修改LMM的分布:
一种是在输入层通过添加一组令牌来修改,这些令牌是LMM条件化的;
另一种是在输出层通过对标准语言模型的多个候选方案进行手术来修改。
方法改进
该论文提出的两种方法改进了传统的测试时间计算方法。第一种方法是直接优化模型以完成给定推理任务,例如使用强化学习启发式微调方法(如STaR或ReSTEM)。第二种方法使模型能够自己改进其自身的建议分布,在测试时指示它批判并修订自己的输出。因此,作者利用针对在复杂推理环境中迭代修订答案的模型进行了微调。
解决的问题
该论文解决了如何最有效地利用测试时间计算来提高语言模型性能的问题。具体来说,作者希望确定在给定提示下使用测试时间计算的最佳方式,并且想知道这种方法是否比使用更大的预训练模型更有效。此外,作者还讨论了如何评估问题的难度以及如何根据问题的难度选择最佳策略。
论文实验
本文主要研究了如何通过调整模型的测试时间计算资源来提高其性能。作者进行了多个对比实验,包括使用验证器和搜索方法对模型进行优化,以及通过修改模型的提议分布来改进模型的性能。具体来说,作者进行了以下实验:
验证器和搜索方法比较实验:该实验旨在比较不同的验证器和搜索方法在不同难度级别的问题上的表现。作者使用了一个基于过程验证器(PRM)的方法,并尝试了三种不同的搜索方法:最佳选择、束搜索和向前搜索。结果表明,在较容易的问题上,使用最佳选择可以达到最好的效果,而在较难的问题上,使用向前搜索可以更好地提高性能。
修改提议分布实验:该实验旨在研究如何通过修改模型的提议分布来改善其性能。作者使用了一种迭代修订模型的方法,并对其进行了训练和测试。结果表明,通过使用迭代修订模型,可以在不增加预训练计算量的情况下显著提高模型的性能。
综上所述,本文的主要结论是,可以通过调整模型的测试时间计算资源来提高其性能。作者提出了一些有效的方法来实现这一目标,并证明这些方法可以在不增加预训练计算量的情况下显著提高模型的性能。
论文总结
文章优点
本文研究了如何在推理时利用额外计算资源来提高大型语言模型(LLM)的性能,并通过实验验证了这种方法的有效性。具体来说,作者提出了一个自适应的“最优计算”策略,可以根据问题难度动态地选择不同的测试时间计算方法,从而最大化模型性能。此外,作者还比较了测试时间和训练时间计算之间的关系,并探讨了如何将测试时间计算结果反馈到基础LLM中以实现迭代改进。
方法创新点
本文的主要贡献在于提出了一种自适应的“最优计算”策略,该策略可以针对不同难度的问题选择最佳的测试时间计算方法。同时,作者还使用了问题难度作为指标来预测测试时间计算的效果,并将其应用于实际场景中的数学推理任务。这些方法对于优化大型语言模型的性能具有重要意义。
未来展望
尽管本文提出的自适应“最优计算”策略已经取得了很好的效果,但仍然存在一些局限性和未来的研究方向。例如,目前的方法主要集中在解决数学推理任务上,而在其他领域的应用还需要进一步探索。另外,如何更好地评估测试时间计算的效果以及如何将测试时间计算的结果与训练时间计算结合起来,也是值得深入研究的方向。
在测试时优化LLM的计算比扩大模型参数更有效
查理·斯奈尔♦,1,李在焕2,金文旭♣,2和阿维拉尔·库马尔♣,2
♣同等建议,1UC伯克利大学,2谷歌DeepMind,♦在谷歌DeepMind实习期间完成的工作
通过使用更多的测试时间计算来提高LLMs的输出,是构建可以处理开放式自然语言任务的一般自我改进代理的关键步骤。在本文中,我们研究了LLM中的推理时间计算的扩展,并重点回答以下问题:如果允许LLM使用固定但非平凡量的推理时间计算,则它可以在具有挑战性的提示上改善其性能吗?回答这个问题不仅会影响LLM可实现的性能,还会影响LLM预训练的未来以及如何权衡推理时间和预训练计算。尽管它的意义重大,但很少有研究试图理解各种测试时间推理方法的扩展行为。此外,当前的工作主要提供了对这些策略的大量否定结果。在这项工作中,我们分析了两种主要机制以扩展测试时间计算:(1)针对密集、基于过程验证器奖励模型进行搜索;和(2)根据测试时间提示更新模型的响应分布。我们发现,在这两种情况下,不同方法扩展测试时间计算的有效性取决于提示的难度。这一观察促使采用“计算最优”的扩展策略,该策略会根据每个提示有效地分配测试时间计算。使用这种计算最优策略,我们可以将测试时间计算扩展的效率提高超过4倍,与最佳N个基线相比。此外,在FLOPS匹配评估中,我们发现对于较小的基本模型能够达到一定程度的成功率的问题,测试时间计算可以用于超越14倍更大的模型。
1.介绍
人类倾向于在困难的问题上花费更多的时间,以可靠地改善他们的决策[9、17、18]。我们能否将类似的能力注入到今天的大型语言模型(LLM)中?更具体地说,在给定一个具有挑战性的输入查询时,是否可以允许语言模型在测试时间最有效地利用额外的计算,从而提高其响应的准确性?理论上,通过在测试时间应用额外的计算,LLM应该能够做得比它所训练的更好。此外,这种能力在测试时间也有潜力解锁新的代理和推理任务的新途径[28、34、47]。例如,如果预训练模型大小可以在推理期间用作交换,则这将使LLM部署成为可能,其中可以在设备上使用较小的模型来代替数据中心规模的LLM。通过使用额外的推断时间计算自动生成改进后的模型输出也提供了一条通向一种通用自我改进算法的道路,该算法可以通过减少人类监督来运行。
先前的工作研究了推理时的计算,结果参差不齐。一方面,一些工作表明当前的LLM可以通过使用测试时间计算来改善其输出[4、8、23、30、48];另一方面,其他工作表明这些方法在诸如数学推理等更复杂任务上的有效性仍然受到高度限制[15、37、43],尽管推理问题通常需要对现有知识进行推断而不是新知识。这些矛盾的结果促使我们系统地分析不同方法的测试时间计算规模。
第 2 页
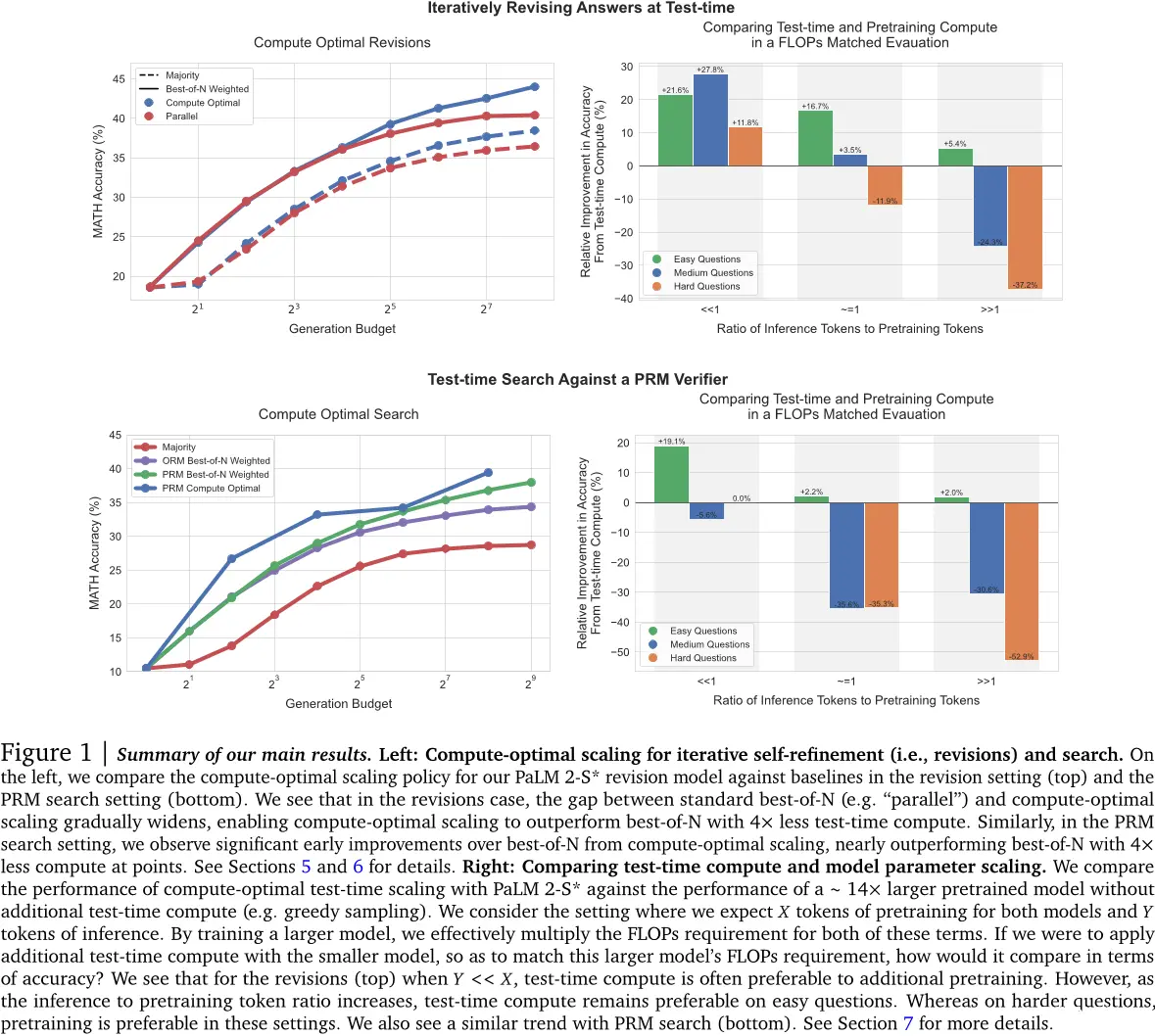
图1 | 我们的主结果的总结。左:迭代自我完善(即修订)和搜索的计算优化缩放。在左边,我们比较了我们的PaLM 2-S修订模型与修订设置中的基线(顶部)以及PRM搜索设置中的计算优化缩放策略。我们看到,在修订的情况下,标准最佳N(例如“并行”)和计算优化缩放之间的差距逐渐扩大,使计算优化缩放能够以测试时间计算量减少四倍来超过最佳N。同样,在PRM搜索设置中,我们观察到从计算优化缩放相对于最佳N获得显著早期改进,几乎在计算量减少四倍时就超过了最佳N。有关详细信息,请参阅第5节和第6节。右:比较测试时间计算和模型参数缩放。我们将计算优化测试时间缩放性能与PaLM 2-S进行比较,而没有额外的测试时间计算(例如贪婪采样)。我们考虑两种模型都预训练X个令牌、Y个令牌进行推理的情况。通过训练更大的模型,我们可以有效地将这两种术语的要求乘以FLOPs。如果我们使用较小的模型应用额外的测试时间计算,以便匹配该更大模型的FLOPs要求,那么它在准确性方面会如何表现?我们看到,在修订(顶部),当Y << X时,测试时间计算通常优于额外预训练。然而,随着推理到预训练令牌比率的增加,测试时间计算仍然在容易的问题上占优势。而在更难的问题上,则是在这些设置中,预训练是首选。我们也看到了类似的趋势与PRM搜索(底部)。请参阅第7节获取更多细节。
为了理解扩展测试时间计算的好处,我们使用专门针对修订进行微调的PaLM-2模型在具有挑战性的MATH基准上进行了实验。
第 3 页
错误答案[28](例如,改善建议分布;第6节)或使用基于过程的奖励模型 (PRM)[22、45] (第5节)验证答案中每个步骤的正确性。通过这两种方法,我们发现特定测试时间计算策略的有效性取决于具体问题的性质和基础LLM。例如,在较容易的问题上,对于基础LLM可以轻松生成合理响应的问题,允许模型迭代地改进其初始答案,预测一系列N个修订(即修改建议分布),可能比在并行采样N个独立响应更有效地利用测试时间计算。另一方面,对于需要搜索许多不同的高级解决方案来解决该问题的困难问题,重新平行采样新响应或将树搜索部署到基于过程的奖励模型可能是更有效利用测试时间计算的方法。这一发现表明了需要部署一种适应性的“计算优化”策略以扩展测试时间计算,其中根据提示选择利用测试时间计算的具体方法,以便充分利用额外的计算资源。我们也展示了从基础LLM的角度来看,一个问题的难度概念(第4节)可用于预测测试时间计算的有效性,使我们在给定提示的情况下能够实际实现这种“计算优化”的策略。通过这种方式适当地分配测试时间计算,我们可以大大提高测试时间计算的扩展性能,并且仅使用约4倍的计算量即可超越最佳的N个基线(第5节和第6节)。
然后,我们使用改进的测试时间计算缩放策略来了解测试时间计算在多大程度上可以有效地替代额外预训练。我们对一个较小模型和一个具有额外测试时间计算的较大模型进行FLOPS匹配比较,并预先训练一个14倍更大的模型。我们发现,在容易和中等难度的问题以及困难问题(具体取决于预训练和推理工作负载的具体条件)上,额外的测试时间计算通常优于扩展预训练。这一发现表明,与其纯粹关注扩展预训练,有些情况下更有效的方法是预先训练较小的模型并应用较少的计算,然后再通过测试时间计算来改善输出。然而,对于最困难的问题,我们观察到很少从扩展测试时间计算中受益。相反,我们在这些问题上发现,通过应用更多的预训练计算取得进展更为有效,这表明当前扩展测试时间计算的方法可能无法与扩展预训练完全交换。总体而言,这表明即使采用相对简单的研究方法,扩展测试时间计算也可以比扩展预训练更加有效,随着测试时间策略的成熟,还可以获得进一步的改进。长期来看,这暗示着未来将花费更少的FLOPS用于预训练,而更多地用于推理。
2. 测试时计算的统一观点:提议者和验证者
我们首先统一测试时间计算的使用方法,然后分析一些代表性方法。首先,我们将额外的测试时间计算视为在测试时间修改模型预测分布的一种方式,条件是给定提示。理想情况下,测试时间计算应该修改分布以生成比从LLM本身随机采样更好的输出。一般来说,有两把调节器可以诱导对LLM分布进行修改:(1)输入级别:
由于这些能力在强大的专有LLM中也不存在。然而,我们预计未来模型将更有效地进行验证和修订,因为规模的增加以及针对这些能力专门收集的数据的加入[5、24、36]。因此为了理解测试时间计算的扩展性,我们必须使用针对这些能力进行微调的模型。不过话说回来,我们预计未来的模型会直接预训练以具备这些能力,从而避免了特定能力的微调需求。
第 4 页
通过在给定提示中增加一组LLM条件的额外令牌,以获得修改后的分布,或者(2)在输出级别:从标准语言模型中采样多个候选者,并对这些候选者进行手术。换句话说,我们可以通过修改由LLM本身诱导的建议分布来使其优于直接基于提示进行条件化,也可以使用一些后处理验证器或评分器来进行输出修改。这个过程类似于Markov链蒙特卡罗(MCMC)[2]从复杂的目标分布中采样,但它是通过结合一个简单的提议分布和一个得分函数来实现的。直接修改输入令牌并使用验证器是我们的研究的两个独立轴之一。
修改建议分布。一种改进建议分布的方法是直接通过RL启发式微调方法,如STaR或ReSTEM对给定的推理任务优化模型(35、50)。请注意这些技术不利用任何额外输入令牌,而是专门针对特定任务来调整模型以产生更好的建议分布。相反,自批评技术(4、8、23、30)允许在测试时间由模型本身迭代地改善其自己的建议分布,即指示它对自己的输出进行批判和修订。由于提示现成模型无法有效地在测试时间实现有效的修订,我们专门针对复杂推理场景对模型进行迭代修订。为此,我们使用了基于最佳N个指导改进的模型响应的有政策数据微调方法(28)。
优化验证器。在我们对建议分布和验证器的抽象中,验证器用于从建议分布聚合或选择最佳答案。使用此类验证器最常用的方法是通过应用最佳N采样,其中我们采样N个完整的解决方案,并根据验证器[7]选择最好的一个。然而,这种方法可以通过训练过程验证器进一步改进[22],或者过程奖励模型(PRM),它产生每个中间步骤的正确性预测,而不是仅仅最终的答案。然后我们可以利用这些每一步的预测来执行解决方案空间中的树搜索,从而相对于简单的最佳N[6、10、48]提供一种可能更有效率和有效的验证方法。
如何优化测试时间计算的规模
鉴于各种方法的统一,我们现在想了解如何最有效地利用测试时间计算来提高给定提示下LM性能。具体来说我们希望回答:
问题设置
我们被给予一个提示和在其中解决该问题的测试时间计算预算。根据上述抽象,可以在测试时间内利用不同的方法来使用计算资源。这些方法中的每一种可能取决于具体的问题而更加或更少有效。如何确定对给定提示最有效的利用测试时间计算的方法?这种方法与简单地使用更大的预训练模型相比会表现得怎么样呢?
在对建议分布进行精炼或与验证器进行搜索时,有几种不同的超参数可以调整以确定测试时间的计算预算应如何分配。例如,在使用经过修订模型作为建议分布和ORM作为验证器的情况下,我们可以将整个测试时间计算预算用于同时从模型中生成N个独立样本,并然后应用最佳的N个,或者我们可以在序列中采样N次修订并然后选择序列中的最佳答案,或者在这些极端之间取得平衡。直觉上,我们可能会期望“更容易”的问题受益于更多的修订,因为
第 5 页
模型的初始样本更有可能在正确的轨道上,但可能需要进一步细化。另一方面,具有挑战性的问题可能需要探索不同的高级问题解决策略,因此在这种情况下并行独立采样可能是首选。
在验证器的情况下,我们也有选择不同搜索算法(例如,beam-search、lookahead-search、best-of-N)的选项,每个算法可能取决于手头的验证器和建议分布而表现出不同的特性。与最佳N或多数基准相比,在更困难的问题中,更复杂的搜索程序可能会更有用。
3.1 测试时计算优化缩放策略
因此,我们希望在给定问题下选择测试时间计算预算的最佳分配。为此,对于任何利用测试时间计算的方法(例如,在本文中使用验证器的修订和搜索,以及其他地方的各种方法),我们将“测试时间计算最优缩放策略”定义为选择对应于给定测试时间策略的最大性能收益的超参数的策略。正式地,将Target (θ ,N,q ) 定义为模型对给定提示q诱导出的自然语言输出令牌分布,并且使用测试时间计算超参数θ ,以及一个计算预算N 。 我们希望选择最大化目标分布准确性的超参数θ 。
其中,y∗(q)表示问题q的正确答案,θq∗,y∗(q)(N)表示在计算预算为N的情况下对问题q进行测试时的最佳缩放策略。
3.2. 计算最佳缩放的难度估计问题
为了有效地分析第2节中讨论的不同机制的测试时间缩放特性(例如,建议分布和验证器),我们将对给定提示的统计量进行优化策略θq∗,y∗(q)(N)的近似值。该统计量估计了给定提示的难度。计算最优策略定义为该提示难度的函数。尽管只是方程1所示问题的一个近似解,但我们发现它仍然可以诱导相对于分配此推理时间计算的基准策略在一种非结构化或均匀采样的方式上的显著性能改进。
我们对问题难度的估计将给定的问题分配到五个难度级别中的一个。然后,我们可以使用这种离散难度分类来估算验证集上的θq∗,y∗(q)(N)。对于给定的测试时间计算预算,我们应用这些计算优化策略于测试集上。具体来说,我们独立地选择每个难度桶中表现最佳的测试时间计算策略。在这种方式下,问题难度在设计计算优化策略时充当了充分统计量的角色。
定义问题的难度。遵循Lightman等人[22]的方法,我们把问题的难度定义为给定基础LLM的一个函数。具体来说,我们将模型在测试集中的每个问题上的通过率(从2048个样本估计)划分为五个量级,每个对应于增加的难度级别。我们发现这种特定于模型的难度划分比手工标记的难度划分更能够预测使用测试时计算的有效性,而不是在MATH数据集中使用的手动标注的难度划分。
但是,我们确实注意到,如上所述评估问题的难度假设可以访问一个正确的答案检查函数,当然在部署时是不可用的。
第 6 页
只有访问我们不知道答案的测试提示。为了在实践中可行,需要首先评估难度,并且使用合适的缩放策略来解决这个问题。因此,我们通过模型预测的难度概念来近似问题的难度,该概念对每个问题上的2048个样本集进行平均最终答案得分(而不是基于地面真实答案正确性检查)执行相同的分箱程序。我们将这种设置称为模型预测难度和依赖于地面真实答案正确性的设置称为oracle难度。
虽然模型预测的难度消除了需要知道真实标签的需求,但通过这种方式估计难度仍然会在推理过程中产生额外的计算成本。不过,这种一次性的推理成本可以包含在实际运行推理时策略的成本中(例如,在使用验证器的情况下,可以使用相同的推理计算来运行搜索)。更一般地说,这类似于强化学习中的探索-利用权衡:在实际部署条件下,我们必须平衡评估难度所花费的计算量与应用最高效的计算方法之间的关系。这是未来工作的一个关键方向(见第8节),我们的实验没有考虑这一成本主要是为了简单起见,因为我们旨在展示有效分配测试时间计算后实际上可能实现的一些结果。
为了避免使用相同的测试集计算难度桶和选择计算最优策略时的混淆因素,我们对每个测试集中的难度桶进行两折交叉验证。根据在其中一个折上的性能表现来选择最佳策略,并且用该策略测量另一个折上的性能表现,反之亦然,平均两个测试折的结果。
实验设置 4。
我们首先概述了进行此分析的多个验证器设计选择和提案分布的实验设置,然后在随后的部分中给出了分析结果。
数据集。我们期望在模型已经具备回答问题所需的基本“知识”的情况下,测试时的计算会最有帮助,并且主要挑战在于从这些知识中进行复杂的推理。为此,我们关注MATH[13]基准,它由高中竞赛级别的数学问题组成,难度水平各不相同。对于所有实验,我们使用Lightman等人[22]使用的包含12000个训练和500个测试问题的数据集划分。
模型。我们使用PaLM 2-S*3基线模型进行分析。我们认为该模型代表了当今许多大型语言模型的能力,因此认为我们的发现可能适用于类似模型。最重要的是,这个模型在MATH上取得了非同寻常的性能,但尚未饱和,所以我们预计这个模型将为我们提供一个良好的测试平台。
通过验证器进行测试时的计算扩展。
在本节中,我们分析了如何通过优化验证器来扩展测试时计算,尽可能有效地进行。为此,我们研究了使用过程验证器(PRM)执行测试时搜索的不同方法,并分析了这些不同方法的测试时计算扩展属性。
5.1. 可以进行搜索的验证者培训
PRM训练。最初,PRM训练[22,42]使用人类的众包标签。而Lightman等人[22]发布了他们的PRM训练数据(即PRM800K数据集),我们发现这些数据大部分是
第 7 页
对我们来说是无效的。我们发现,即使使用最简单的策略(如最佳N采样),也可以很容易地利用在该数据集上训练的PRM进行攻击。我们推测这可能是由于GPT-4生成样本和我们的PaLM 2模型之间的分布偏移造成的。而不是继续收集用于监督我们PaLM 2模型的昂贵的人工标注PRM标签的过程,我们应用了Wang等人[45]的方法来监督没有人类标签的PRM,通过从每个解决方案步骤运行蒙特卡洛展开估计每一步的正确性。因此,我们的PRM的每一步预测对应于基线模型采样策略的奖励到去价值估计,类似于最近的工作[31、45]。我们也比较了一个ORM基准(附录F),但发现我们的PRM始终优于ORM。因此,本节的所有搜索实验都使用PRM模型。关于PRM训练的更多细节请参见附录D。
答案聚合。在测试时间,过程验证器可以用于为从基模型中采样的一组解决方案中的每个步骤打分。为了使用PRM选择最佳的N个答案,我们需要一个函数来汇总所有答案的所有步骤分数以确定正确的答案的最佳候选者。为此,我们首先将每个答案的每个步骤分数汇总到最终答案(逐步汇总)。然后,我们将答案进行汇总以确定最佳答案(跨答案汇总)。具体来说,我们按照以下方式处理逐步和跨答案汇总:
• 步骤级聚合。我们不使用乘积或最小值(如 [22,45])来汇总每个步骤的得分,而是将最后一步的PRM预测作为完整答案的分数。我们在研究的所有汇总方法中发现这种方法表现最好(见附录E)。
• 问题答案的聚合。我们遵循Li等人[21]的做法,采用“最佳N加权”的选择而不是标准的最佳N。最佳N加权的选择在所有具有相同最终答案的所有解决方案中平均化验证者的正确性分数,并选择总和最大的最终答案。
5.2. 对PRM的搜索方法
我们在测试时间通过搜索方法优化PRM。我们研究了三种搜索方法,这些方法从少量提示的基线LLM中采样输出(见附录G)。图2显示了一个示例。
最佳N加权。我们从基础LLM中独立地采样N个答案,然后根据PRM的最终答案判断选择最好的答案。
束搜索。束搜索通过在每个步骤的预测上进行搜索来优化PRM。我们的实现类似于BFS-V [10,48] 。具体来说,我们考虑固定数量的束N和束宽度M。然后运行以下步骤:
对于解决方案的第一步,对初始预测进行N个样本。
根据PRM预测的步进奖励估计值对生成步骤进行评分(这与前缀的总奖励相对应,因为在这个设置中奖励是稀疏的)
只过滤前N个M最高得分的步骤
再次输入候选前缀。然后重复步骤2-4。
我们运行此算法直到解决方案的结束或最大束扩展轮数达到(在我们的案例中为 40)。我们通过应用上述最佳的 N 权重选择来结束搜索,以对最终答案进行预测。
第 8 页
前瞻搜索。前瞻搜索修改了如何使用束搜索评估单个步骤。它通过使用前瞻展开来提高在搜索过程中每个步骤的PRM价值估计的准确性。具体来说,在束搜索中的每一步,而不是使用当前步骤的PRM分数来选择顶级候选者,前瞻搜索会进行模拟,向前展开最多k步,并且如果达到解决方案的终点,则提前停止。为了最小化模拟展开的方差,我们使用温度为0进行展开。然后将此展开结束时的PRM预测用于评分束搜索中的当前步骤。换句话说,我们可以将束搜索视为具有k = 0的前瞻搜索的一种特殊情况。给定准确的PRM,增加k应该可以改善每个步骤的价值估计,但需要额外计算。请注意,这种版本的前瞻搜索是MCTS [38] 的一种特殊情况,其中设计以促进探索的MCTS的随机元素被移除,因为PRM已经训练并且冻结。这些随机元素对于学习值函数(我们已经通过我们的PRM学习)非常有用,但在测试时间我们想要利用而不是探索时则不太有用。因此,前瞻搜索主要代表了MCTS风格的方法在测试时间的应用。
5.3. 分析结果:验证器搜索的测试时间缩放
我们现将各种搜索算法的比较结果展示出来,并且识别出一种搜索方法依赖于提示难度的计算最优缩放策略。
比较搜索算法。我们首先对各种搜索设置进行一次扫描。除了标准的N个最佳方法外,我们还扫过两个主要参数:区分不同树搜索方法的主要参数M和k。虽然我们无法广泛地扫描每个配置,但我们以最大预算为256扫描以下设置:
1)使用beam宽度为√N的beam搜索,其中N是生成预算。
2)固定宽度为4的束搜索。
第 9 页
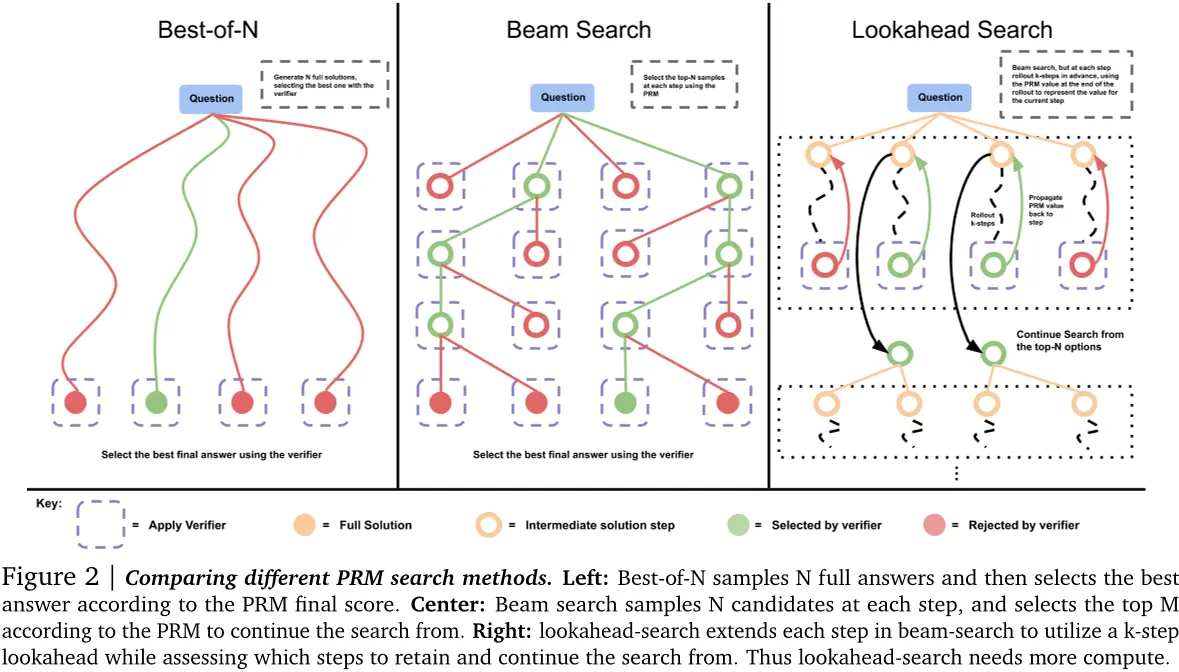
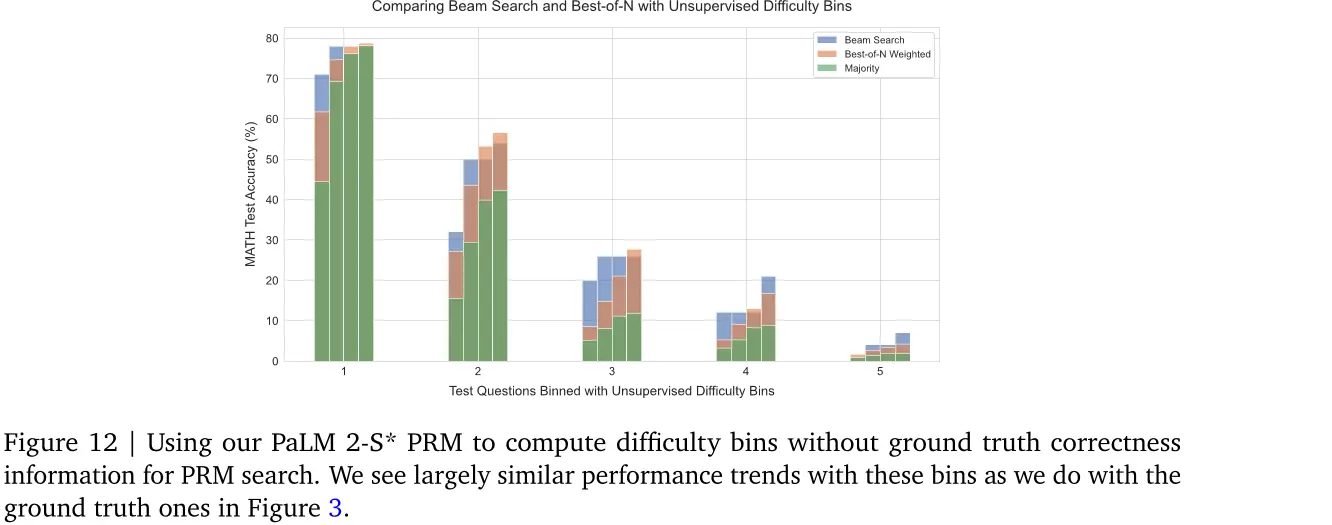
图3 | 左:比较不同方法进行PRM验证器搜索。我们看到在低生成阶段
预算,beam搜索表现最佳,但随着我们进一步扩大预算,改进幅度减小,低于最佳的N个基准。前瞻搜索在相同生成预算时通常不如其他方法。右:比较beam搜索和按难度水平划分的最佳的N个。每个难度桶中的四个条形图对应于增加的测试时间计算预算(4、16、64 和 256 代)。对于较容易的问题(桶 1 和 2),随着预算的增加,beam搜索显示出过度优化的迹象,而best-of-N 不是这样。对于中等难度问题(桶 3 和 4),我们看到beam搜索在best-of-N上表现出一致的改进。
3)使用k = 3进行前瞻搜索,应用于设置1)和2)。
4)应用k = 1的前瞻搜索到beam搜索设置1)。
为了公平地比较搜索方法的生成预算,我们建立了一个估算每个方法的成本的协议。我们认为一个生成是基线LLM的一个采样答案。对于beam搜索和best-of-N,生成预算对应于相应的光束数和N。然而,lookahead搜索利用了额外的计算:在每次搜索步骤中,我们采样k个额外的步骤。因此,我们将lookahead搜索的成本定义为N×(k + 1)样本。
结果。如图3(左)所示,随着生成预算的减少,beam搜索显著优于best-of-N。然而,在增加预算时,这些改进大大降低,有时beam搜索甚至不如best-of-N基准。我们还看到,lookahead-search在相同的生成预算下通常会低于其他方法,这可能是因为模拟lookahead rollout所引入的额外计算所致。搜索带来的回报递减可能是由于利用了PRM的预测。例如,我们在一些实例中(如图29所示),搜索导致模型在解决方案的末尾产生低信息重复步骤。在其他情况下,我们发现过度优化搜索会导致过于简短的解决方案,仅包含1-2个步骤。这解释了为什么最强大的搜索方法(即lookahead搜索)表现不佳的原因。我们在附录M中包括了一些由搜索找到的例子。
搜索改进了哪些问题?为了理解如何计算优化地扩展搜索方法,我们现在进行难度箱分析。具体来说,我们比较beam-search(M = 4)和best-of-N。在图3(右)中,我们可以看到,在总体上,beam search和best-of-N在高生成预算时表现相似,但评估它们的有效性对难度箱显示非常不同的趋势。对于容易的问题(水平1和2),两种方法中的更强的优化器,beam search随着生成预算增加而降低性能,表明PRM信号被利用的迹象。相反,对于更难的问题(水平3和4),beam search始终优于best-of-N。对于最困难的问题(水平5),没有方法取得有意义的进步。
第 10 页
这些发现符合直觉:我们可能会期望在容易的问题上,验证者会做出大部分正确的评估。因此,通过进一步优化(使用beam搜索),只会进一步放大验证器学到的任何虚假特征,导致性能下降。对于更难的问题,基础模型更不可能首先采样出正确答案,所以搜索可以用来帮助引导模型更多地产生正确的答案。
计算优化搜索。根据上述结果,很明显问题的难度可以是一个有用的统计信息来预测在给定计算预算时使用最佳搜索策略。此外,在此难度统计指标下,选择搜索策略的最佳选择可能会有很大的变化。因此,我们可视化了“计算优化”的缩放趋势,如图4中每个难度级别上表现最好的搜索策略所示。我们看到,在低生成预算范围内,同时使用oracle和预测难度,计算优化缩放几乎可以比best-of-N少用4倍的测试时间计算(例如,16代与64代)。而在更高的预算范围内,这些好处随着使用预测难度而减少,但使用oracle bin仍然可以看到从优化测试时间计算中获得的持续改进。这个结果表明,在搜索过程中通过适应性分配测试时间计算可以获得性能收益。
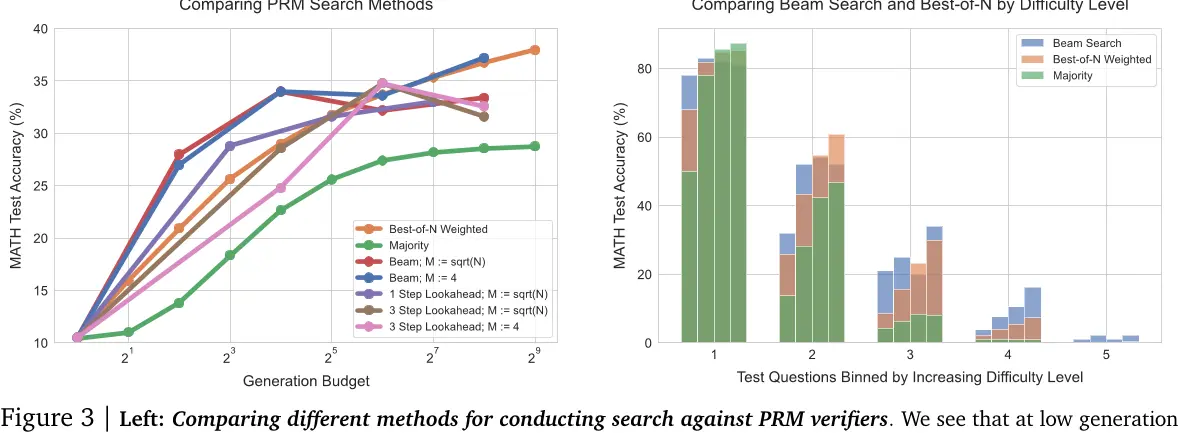
图4:比较计算优化的测试时间计算分配与基于PRM搜索的基线。通过按问题难度的概念来扩展测试时间计算,我们发现我们可以使用最多4倍少于测试时间计算(例如,16对64代)来近乎超过PRM最佳N。"计算优化的oracle"是指使用来自ground truth正确性信息的oracle难度桶,并且“计算优化预测”是指使用PRM的预测生成难度桶。“计算优化的oracle”和“计算优化预测”的曲线几乎重叠在一起。
计算优化的验证器缩放的要点
我们发现,任何给定的验证器搜索方法的有效性都取决于计算预算和问题本身。具体来说,在更难的问题上以及在更低的计算预算下,beam-search 更有效;而在更容易的问题上以及在更高的预算下,best-of-N 更有效。此外,通过选择针对特定问题难度和测试时间计算预算的最佳搜索设置,我们可以使用最多四倍少于测试时间计算来近乎超越 best-of-N。
6. 提炼建议分布
到目前为止,我们研究了搜索对验证器的测试时间计算缩放属性。现在我们将转向研究修改建议分布的缩放属性(第2节)。具体来说,我们使模型能够迭代地修订自己的答案,允许模型在测试时动态改进其自身的分布。简单地提示现有的LLM来纠正自己的错误往往对于推理问题的性能提升效果不大[15]。因此,我们基于Qu等人[28]所规定的配方,结合我们的设置进行修改,并微调语言模型以迭代地修订自己的答案。首先,我们描述如何训练和使用通过顺序条件来修订自己提议分布的模型。然后,我们分析了修订模型的推断时间缩放属性。
第 11 页
6.1 设置:训练和使用修订模型
我们对修订模型进行微调的程序与[28]类似,尽管我们引入了一些关键差异。对于微调,我们需要轨迹,即一系列错误答案后跟着一个正确答案,然后我们可以运行SFT。理想情况下,我们希望正确的答案与在上下文中提供的错误答案相关联,以便有效地教给模型识别出在上下文中的示例中出现的错误,并通过编辑而不是忽略整个上下文示例来纠正这些错误,然后再从头开始尝试。
生成修订数据。Qu等人[28]的在策略上的方法用于获取多个多轮次回放,被证明是有效的,但我们的基础设施由于运行多轮次回放所涉及的计算成本而无法完全实现。因此,我们并行地以较高的温度采样了64个响应,并且从这些独立样本后置构建了多轮次回放。具体来说,遵循[1]中的食谱,我们将每个正确的答案与来自此集合的一系列错误的答案配对作为上下文来构造多轮次微调数据。我们在上下文中最多包含四个错误的答案,在上下文中的特定数量的解决方案是从类别0到4之间的均匀分布中随机采样的。我们使用字符编辑距离度量优先选择与最终正确答案相关的错误答案(见附录H)。请注意,令牌编辑距离不是完美的相关性衡量标准,但我们发现这个启发式方法足以将与正确目标答案相关的上下文中的错误答案与无关的响应进行配对,从而训练出有意义的修订模型,而不是随意地将错误和正确的响应与不相关的响应进行配对。
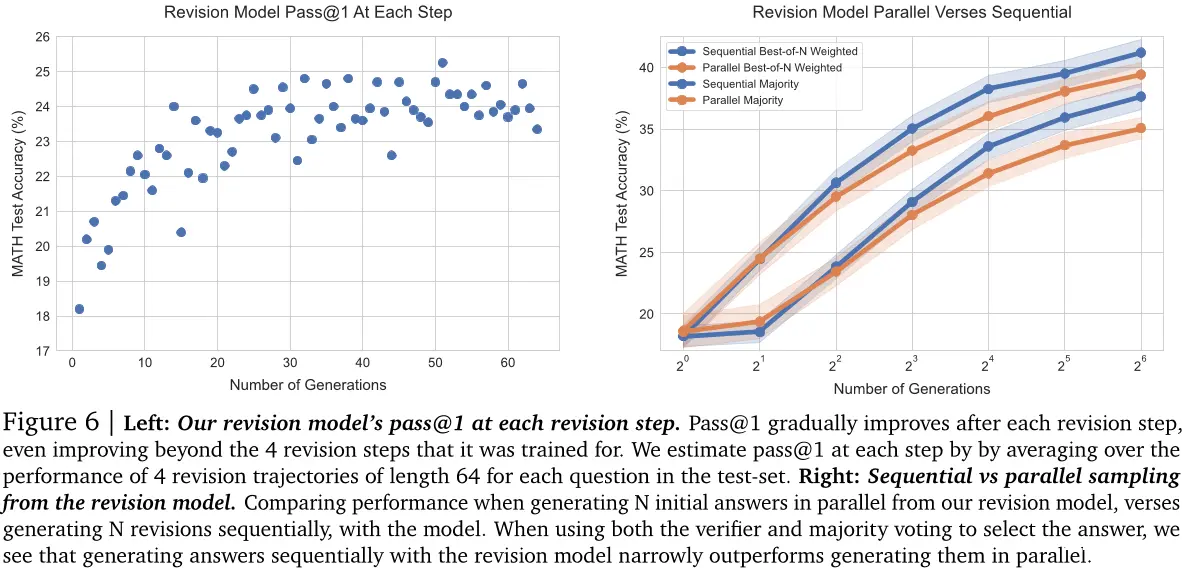
在推理时使用修订。给定一个经过微调的修订模型,我们可以在测试时间从该模型中采样一系列修订。虽然我们的修订模型仅在上下文中训练最多四个先前的答案,但我们可以通过截断上下文到最近四个修订后的响应来采样更长的链。如图6(左)所示,在我们从修订模型中采样更长的链后,随着每个步骤的进行,模型的pass@1逐渐提高,这表明我们可以有效地教模型学习如何从上下文中的先前答案所犯的错误中吸取教训。
第 12 页
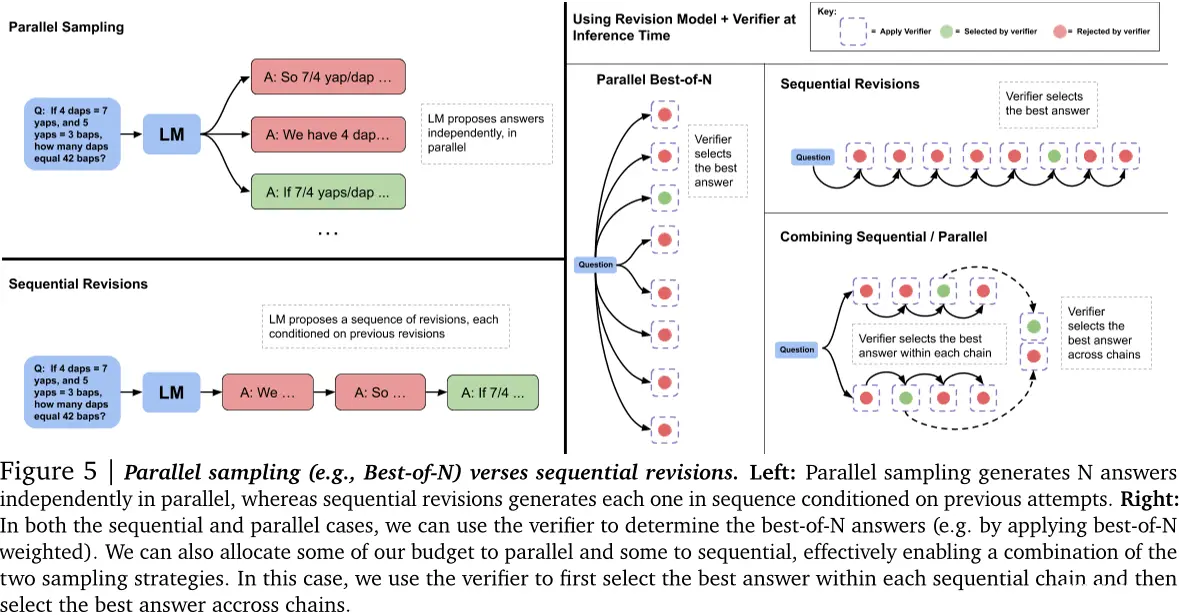
但是,正如所言,在推理时存在分布偏移:模型仅在上下文中包含错误答案的序列上进行训练,但在测试时间,模型可能会采样包含在上下文中的正确答案。在这种情况下,它可能无意中将正确的答案变成下一个修订步骤中的错误答案。我们发现,确实如Qu等人[28]所述,我们的修订模型使用一种简单的方法,约有38%的正确答案被转换为错误的答案。因此,我们采用基于顺序多数投票或验证器选择机制来从模型制作的修订序列中选出最正确的答案(见图5),以产生最佳答案。
比较。为了测试通过修订修改建议分布的有效性,我们设置了一个在序列中采样N次修订和并行采样N个问题的性能之间的平衡比较。我们在图6(右)中看到,在两种基于验证器的选择机制下,序列采样解决方案优于并行采样它们。
6.2 分析结果:修订后的测试时间缩放
我们之前看到,顺序地提出答案比并行地提出答案表现更好。然而,我们可能会期望顺序和并行采样具有不同的特性。并行采样可能更像一个全局搜索过程,在原则上可以提供对解决一个问题的许多完全不同的方法的覆盖,例如,不同候选者可能使用完全不同的高级方法。另一方面,顺序采样可能更多地作为局部精炼过程工作,修订已经有点正确的回答。由于这些互补的好处,我们应该在这些极端之间取得平衡,并分配一些我们的推理时间预算到并行采样(例如√N)和其余部分用于顺序修订(例如√N)。现在我们将展示顺序和并行采样的计算最优比率的存在性,并根据给定提示的难度理解它们的相对优缺点。
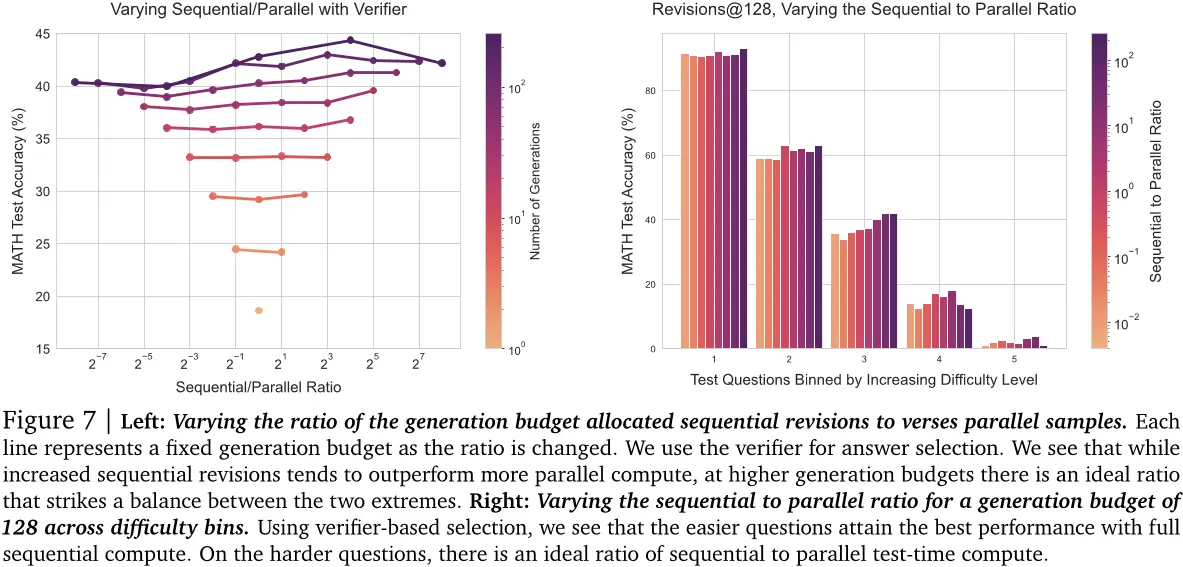
交易顺序和并行测试时间计算。为了理解如何最佳分配顺序和并行计算,我们对一系列不同的比率进行扫描。我们在图7(左)中看到,在给定的代数预算下确实存在一个理想的顺序到并行比率,即
第 13 页
达到最大精度。我们还看到,在图7(右)中,顺序和并行计算的比例取决于问题的难度。具体来说,简单的问题从顺序修订中受益更多,而困难的问题则需要在顺序和并行计算之间取得平衡。这一发现支持了假设:顺序修订(即改变建议分布)和并行采样(即使用验证器进行搜索)是扩大测试时间计算的两个互补轴,可能在每个提示的基础上更有效。我们在附录L中包括了我们的模型生成的例子。其他结果见附录B。
计算优化的修订。鉴于序列和并行采样的有效性取决于问题难度,我们可以选择每个难度桶中顺序计算与并行计算的理想比例。在图8中,我们使用了这种计算优化的缩放策略,并且同时采用了我们的oracle和预测难度概念。在两种情况下,通过改进建议分布来提高测试时间缩放性能。特别是,在更高的生成预算下,似乎并行采样达到了饱和点,而计算优化的缩放则继续改善。对于oracle和预测难度桶,我们看到计算优化的缩放可以比最佳N少用4倍的测试时间计算(例如,64个样本对256个)。总体而言,这些结果表明,根据提示调整建议分布可以提高测试时间计算缩放的潜力。
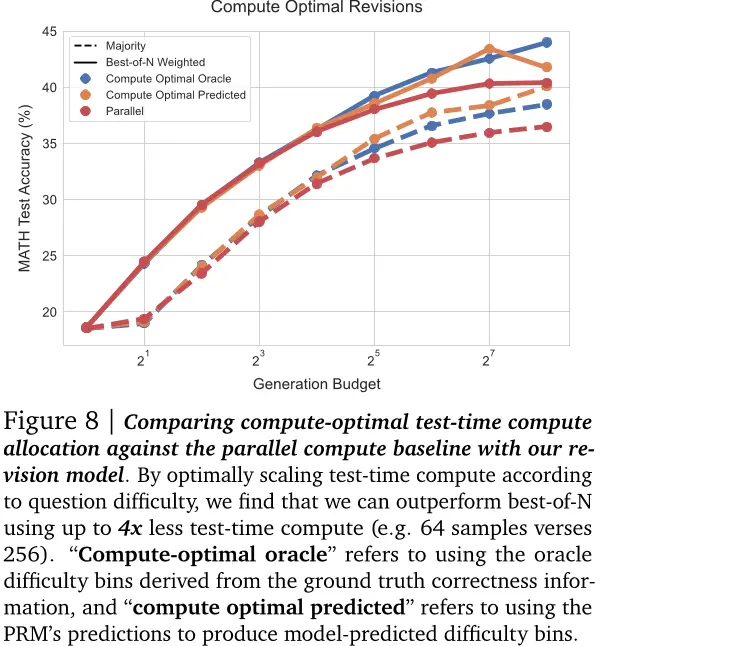
图8:将我们的重新审视模型与平行计算基准进行比较,以在测试时间分配计算。通过根据问题的难度优化地缩放测试时间计算,我们发现我们可以使用最多四倍少于测试时间计算(例如,64个样本对256)来超过最佳N。"计算最优oracle"是指使用来自地面真实正确信息的oracle难度桶,并且“计算最优预测”是指使用PRM的预测生成模型预测难度桶。
第 14 页
通过修订建议分布以优化计算规模的要点
我们发现,序列(例如修订)和并行(例如标准最佳的N个)测试时间计算之间存在权衡关系,并且序列到并行测试时间计算的理想比率取决于计算预算以及具体问题。具体来说,更容易的问题受益于纯粹的序列测试时间计算,而更难的问题通常在某些理想的序列到并行计算比率下表现最好。此外,在给定问题难度和测试时间计算预算的最佳设置上进行最优选择,我们可以使用最多四倍少的测试时间计算来超过并行最佳的N个基准。
7. 组装:交换预训练和测试时的计算
到目前为止,我们看到利用额外的测试时间计算可以让我们代表比基线LLM本身预测的更复杂的分布,从而提高性能。现在我们认为这种表示分布灵活性的增加意味着我们可以期望在预训练期间使用更多的FLOPs或更大的模型来弥补测试时间计算的不足。在这部分中,我们将研究这是否可能。我们提出以下问题:
增加预训练的FLOPS引入了是否分配计算资源给更多数据或更多参数的额外设计决策。我们专注于模型参数规模扩大而训练数据量固定的设置,这与开源LLaMA系列模型采用的方法一致。我们选择这个设置是因为它代表了一种典型的预训练计算扩大的标准方法,并将对预训练计算的最佳扩展进行分析(即数据和参数都以相同的比例进行扩展)留待未来工作。
定义FLOPS之间的汇率。现在我们描述如何定义预训练和推理FLOPS之间的汇率。为了确定预训练FLOPS,使用常见的近似X = 6N Dpretrain [14] ,对于推理FLOPS,我们使用Y = 2N Dinference [29] 。这里N表示模型参数,Dpretrain是用于预训练的令牌数,Dinference是在推理时间生成的总令牌数。有了这些近似值,我们可以看到,如果我们乘以模型参数的一个因子M,则预训练和推理FLOPS(由于更大模型贪婪解码的成本)将增加一个因子M(总共M (X + Y) FLOPS)。
为了匹配通过在测试时间计算中扩展模型参数来增加的FLOPS,我们可以将较小模型的推理计算乘以一个因子(M + 3🟥Dpretrain Dinference)(M - 1)。值得注意的是,我们能够利用多少推理计算来匹配大模型的FLOPS取决于预训练和推理计算的比例。我们把这个比例的倒数称为R(例如,Dinference Dpretrain)。具体生产设置或用例的不同,我们预期R会有非常不同的值。特别是,在许多大规模生产环境中,我们可能期望有比预训练更多的推理令牌,此时我们会有一个R> > 1的情况。另一方面,在许多当代自我改进设置中,这些设置会使用测试时间计算来提高模型性能,我们可能会产生更少的推理令牌。
第 15 页
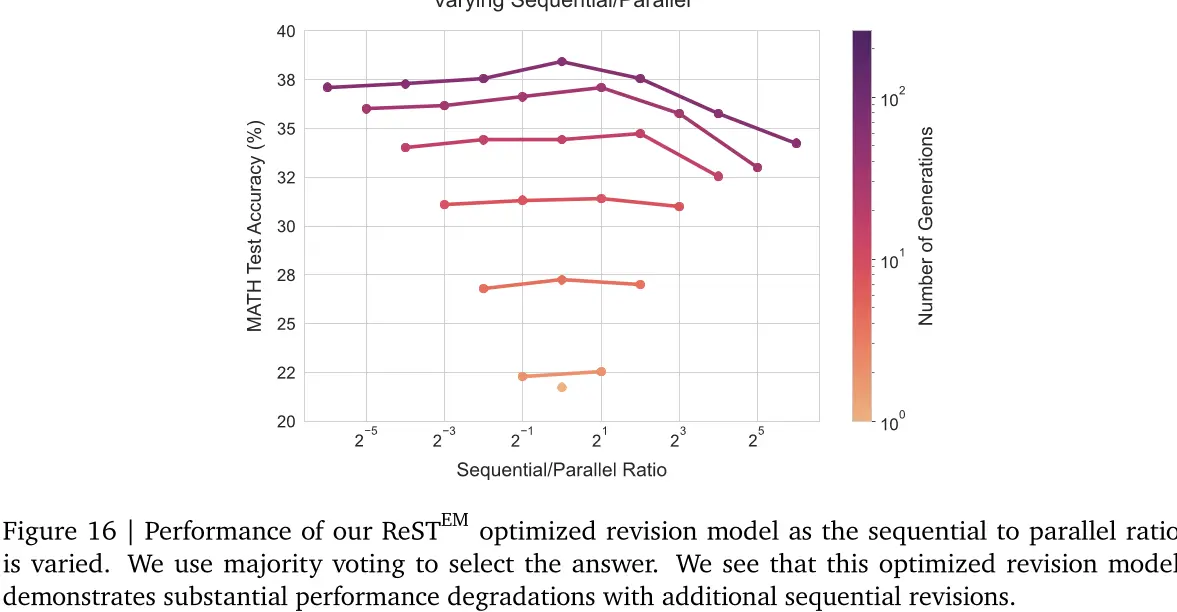
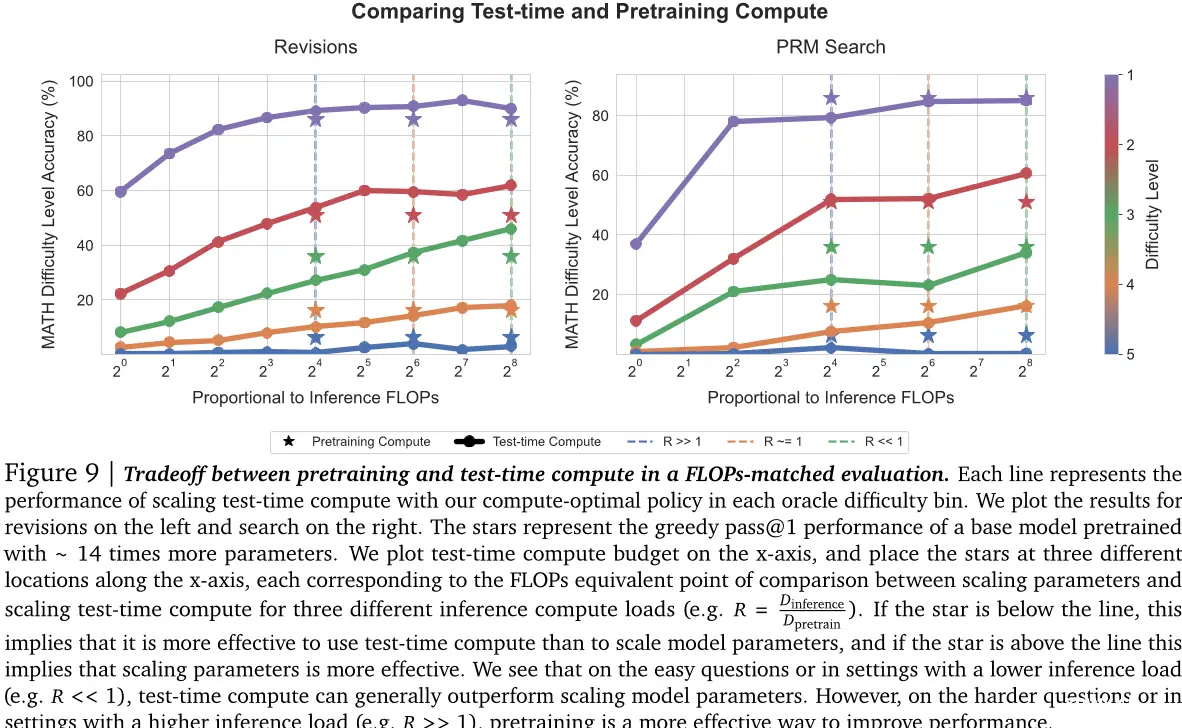
图9 | 在FLOPs匹配评估中,预训练和测试时间计算之间的权衡。每条线代表我们在每个oracle难度桶中使用我们的计算最优策略进行扩展的测试时间计算性能。我们将结果绘制在左侧修订和右侧搜索上。星星表示一个基模型的贪婪通过率@1性能,该模型使用约14倍更多的参数进行了预先培训。我们将测试时间计算预算绘制在x轴上,并沿x轴放置三个不同的位置上的星星,每个对应于比较参数扩展和测试时间计算扩展的FLOPs等效点(例如R = Dinference Dpretrain)。如果星星位于线以下,则表明使用测试时间计算比扩展模型参数更有效;如果星星位于线上方,则表明扩展参数更为有效。我们看到,在容易的问题或具有较低推理负载的情况下(例如R << 1),测试时间计算通常优于扩展模型参数。然而,在困难的问题或具有较高推理负载的情况下(例如R >> 1),预先培训是一种提高性能的有效方法。
推理令牌比预训练令牌多,因此R<<1。因此,由于我们在测试时可以应用的计算规模取决于这个比例,我们期望在特定设置下得出不同的结论。
在图9中,我们使用这种方法来交换测试时间和预训练计算以比较我们的计算优化的缩放与通过因子约为14放大模型参数。我们对R值为:0.16(R << 1),0.79(R ≈ 1)和22(R >> 1)进行比较,每个比率对应一个推理预算。观察到如果仅期望看到非常困难的问题(例如难度桶4/5)或有更大的Dinference(对应于较大的R值),那么通常更有效的是将我们的预算分配给预训练(例如星号高于线)。相反,如果我们预期主要是容易或中级难度问题(例如桶1/2/3有时是4)或具有较低的推理要求(如自我改进管道的情况),则利用测试时间计算更好。
交换预训练和测试时间计算的要点
测试时间和预训练计算不是一对一的“可交换”。在容易和中等的问题上,这些问题是模型能力范围内的问题,或者是在对推理要求较小的情况下,测试时间计算可以轻松地弥补额外的预训练。然而,在具有挑战性的问题上,这些问题超出了给定基线模型的能力范围或需要更高的推理要求,预训练可能更有效提高性能。
8 讨论与未来工作
在这项工作中,我们对旨在改善验证器搜索或细化LLM建议分布的不同技术的有效性进行了全面分析。
第 16 页
用于数学推理。一般来说,我们发现给定方法的有效性与基线LLM能力的难度高度相关。这促使我们引入了“计算优化”的测试时间计算扩展的概念,它建议在给定的测试时间计算预算下采用适应性和提示依赖策略来提高性能。通过应用这种计算优化的扩展策略,我们发现可以将测试时间计算扩展的效率提高2-4倍。当比较额外的测试时间计算带来的好处和额外的预训练计算带来的好处时,在FLOPs匹配的情况下,我们首次表明使用似乎简单的测试时间计算(即修订和搜索)可以在某些类型的提示上很好地扩展,并且比花费这些FLOPs进行预训练更有利。然而,我们的研究也存在一些局限性,未来的工作可以尝试解决这些问题。
进一步提高测试时的计算缩放。在这项工作中,我们专注于改进两个主要机制的测试时间计算缩放:验证器和建议分布(通过修订)。虽然我们在第6节中将验证器与修订相结合,但我们没有在结合修订的情况下实验PRM树搜索技术。我们也未研究其他技术,如批评和修订[23]。未来的工作应该调查如何通过结合这些方法来进一步改善测试时间计算缩放。此外,我们发现,在所有情况下,这些方案对困难问题提供了小的收益;未来的工作应致力于开发新的使用测试时间计算的方法,以绕过这一限制。
快速评估问题的难度。我们使用一个概念来表示问题的难度,作为近似计算最优测试时间缩放策略的一个简单的充分统计量。虽然这种方法有效,但估计我们的难度概念需要在测试时间内应用非平凡数量的计算本身。未来的工作应该考虑更有效地估算问题难度的方法(例如,通过预训练或微调模型直接预测问题难度)或者动态切换评估难度和尝试解决一个问题之间。
将测试时间和训练时间的计算交织在一起。在本工作中,我们专注于测试时间计算的扩展,并且测试时间计算可以被交易以换取额外的预训练的程度。然而,在未来,我们认为应用额外的测试时间计算的结果可以被提炼回基本的LLM中,从而实现一个迭代自我改进循环,该循环操作于开放式的自然语言。为此,未来的研究应该延伸我们的发现并研究如何使用测试时间计算的结果来改善基本的LLM本身。
致谢
我们感谢 Yi Su、Rishabh Agarwal、Yinlam Chow、Aleksandra Faust、Vincent Zhuang、George Tucker、Hao Liu、Jiayi Pan、Ethan Dyer、Behnam Neyshabur、Xavier Garcia、Yamini Bansal、Lampros Lamprou、Yuxiao Qu 和 Amrith Setlur 对论文早期版本的反馈和讨论。我们归因并感谢 Rishabh Agarwal、Vincent Zhuang、Yi Su 和 Avi Singh 提出的想法和讨论,以及在[1]中具体证明了对训练修订模型进行对偶样本生成的前景,并且基于编辑距离采样的实验。我们感谢 Slav Petrov 的领导支持。
参考文献
[1] 使用合成数据训练修订模型。即将推出,2024年。
第 17 页
[2]C. Andrieu,N. De Freitas,A. Doucet和M.I.Jordan。机器学习中的蒙特卡罗链方法介绍。2003年。
[3]R.安利,A.M.戴,O.费拉特,M.约翰逊,D.列皮欣,A.帕索斯,S.沙基里,E.塔罗帕,P.贝利,Z.陈,E.楚,J.H.克拉克,L.E.谢菲,Y.黄,K.梅耶-赫尔斯特伦,G.米什拉,E.莫雷拉,M.奥默尼克,K.罗宾逊,S.鲁德,Y.泰,K.肖,Y.许,Y.张,G.H.阿布雷戈,J.安,J.奥斯汀,P.巴哈姆,J.博塔,J.布拉德伯里,S.布拉马,K.布鲁克斯,M.卡斯塔塔,Y.程,C.樱桃,C.A.乔奎特-朱,A.查杜里,C.克雷皮,S.达维,M.德汉尼,S.德夫,J.德弗林,M.迪亚兹,N.都,E.狄耶,V.费因伯格,F.冯,V.芬伯格,M.弗赖塔格,X.加西亚,S.盖尔曼,L.冈萨雷斯,G.古里-阿里,S.汉德,H.哈希米,L.侯,J.霍兰德,A.胡,J.惠,J.赫尔沃茨,M.伊斯德尔,A.伊蒂切利亚,M.贾吉尔斯基,W.家,K.肯内利,M.克里库恩,S.库杜甘塔,C.兰,K.李,B.李,E.李,M.李,W.李,Y.李,J.李,H.林,Z.刘,F.刘,M.马吉奥尼,A.马亨杜,J.迈内兹,V.米斯拉,M.穆萨莱姆,Z.纳多,J.南姆,E.尼,A.纽斯特朗,A.帕里斯,M.佩勒特,A.波洛佐夫,R.波普,S.乔,E.雷夫,B.里奇,P.里利,A.C.罗斯,A.罗伊,B.塞塔,R.萨缪尔,R.谢尔比,A.斯隆,D.斯米尔科夫,D.R.苏,D.松本,S.托库明,D.瓦尔特,V.瓦斯德万,K.沃德拉哈尔,X.王,P.王,Z.王,T.王,J.威廷,Y.吴,K.徐,Y.徐,L.薛,P.尹,J.于,Q.张,S.郑,C.郑,W.周,D.周,S.彼得罗夫和Y.吴。棕榈2技术报告,2023年。
[4] 白叶,卡达瓦斯,库尔德努,阿斯凯尔,杰克·金恩,艾伦·琼斯,安吉·陈,安吉·戈迪,阿米尔·穆罕默德,克里斯蒂娜·麦克金农,克里斯汀·陈,克里斯汀·奥洛森,克里斯汀·奥拉赫,戴维·赫南德兹,戴维·德拉因,戴维·冈古利,戴维·李,埃里克·特兰-约翰逊,埃里克·佩雷斯,杰夫·柯尔,杰弗里·穆勒,杰夫·拉迪什,杰夫·兰道,凯瑟琳·恩多苏,凯瑟琳·卢科斯维尔,丽贝卡·劳维特,迈克尔·塞利托,纳塔莉亚·埃尔哈格,纳塔莉亚·施费尔,纳塔莉亚·梅尔卡多,纳塔莉亚·达萨玛,罗伯特·拉斯本,罗伯特·拉森,史蒂文·林格尔,史蒂芬·约翰斯顿,史蒂芬·克拉韦克,史蒂芬·E。肖克,史蒂芬·福特,泰勒·兰姆汉姆,泰勒·特莱恩-劳顿,泰勒·康尼尔,泰勒·亨尼根,泰勒·胡姆,史蒂文·R。鲍曼,扎克·哈特菲尔德-杜德斯,布赖恩·曼恩,丹尼尔·阿莫迪,诺亚·约瑟夫,斯蒂芬妮·麦坎迪希,汤姆·布朗,和杰夫·卡普兰。宪法人工智能:从人工智能反馈中消除危害,2022年。
[5] C. Blakeney,M. Paul,B. W. Larsen,S. Owen,and J. Frankle。你的数据能带来喜悦吗?在训练结束时通过域上采样获得的性能提升,2024年。URL:https://arxiv.org/abs/2406.03476。
[6] 陈国,廖敏,李春,范凯。AlphaMath几乎零:无过程的流程监控,2024年。
[7]K. Cobbe,V. Kosaraju,M. Bavarian,M. Chen,H. Jun,L. Kaiser,M. Plappert,J. Tworek,J. Hilton,R. Nakano,C. Hesse,and J. Schulman. 训练验证者解决数学文字问题,2021。
[8] Y. Du,S. Li,A. Torralba,J.B.Tenenbaum和I.Mordatch。通过多代理辩论提高语言模型的客观性和推理能力,2023年。
[9] J.S.B.T.Evans。推理中的启发式和分析过程。英国心理学杂志,75(4):451-468,1984。
[10]X. Feng,Z. Wan,M. Wen,S.M. McAleer,Y. Wen,W. Zhang,and J. Wang. AlphaZero-like tree search can guide large language model decoding and training, 2024。
[11] 高亮,马丹,周思,阿隆,刘鹏,杨阳,卡兰和尼布格。Pal:程序辅助语言模型,2023年。URL https://arxiv.org/abs/2211.10435。
[12]S.Goyal,Z.Ji,A.S.Rawat,A.K.Menon,S.Kumar和V.Nagarajan。在说话之前思考:使用停顿标记训练语言模型,2024年。URLhttps://arxiv.org/abs/2310.02226。
第 18 页
[13]D.Hendrycks,C.Burns,S.Kadavath,A.Arora,S.Basart,E.Tang,D.Song,and J.Steinhardt. 使用数学数据集测量数学问题解决能力,2021。
[14] J. Hoffmann,S. Borgeaud,A. Mensch,E. Buchatskaya,T. Cai,E. Rutherford,D. de Las Casas,L.A.Hendricks,J.Welbl,A.Clark,T.Hennigan,E.Noland,K.Millican,G.van den Driessche,B.Damoc,A.Guy,S.Osindero,K.Simonyan,E.Elsen,J.W.Rae,O.Vinyals,and L.Sifre. 训练计算最优的大语言模型,2022。
[15] 黄杰,陈鑫,米什拉S,郑浩思,Yu AW,宋晓和周大。大型语言模型不能自我纠正推理,2023年。
[16] A.L.Jones. Scaling scaling laws with board games, 2021. URL https://arxiv.org/abs/2104.03113。
[17] D. Kahneman. Maps of bounded rationality: Psychology for behavioral economics. The American Economic Review, 93(5):1449-1475, 2003。
[18]丹尼尔·卡尼曼。《思考,快与慢》。法拉奇、斯特劳斯和吉鲁克斯出版社,纽约,第一版平装本,2013年。
[19] L. Kocsis 和 C. Szepesv'ari。基于博奕的蒙特卡罗规划。在欧洲机器学习会议,第282-293页。Springer出版社,2006年。
[20]A. Lewkowycz,A. Andreassen,D. Dohan,E. Dyer,H. Michalewski,V. Ramasesh,A. Slone,C. Anil,I. Schlag,T. Gutman-Solo,Y. Wu,B. Neyshabur,G. Gur-Ari,and V. Misra. Solving Quantitative Reasoning Problems With Language Models, 2022。
[21] 李亚,林子,张硕,傅强,陈斌,刘杰刚,陈伟。基于步骤感知验证器的大型语言模型推理能力提升,2023。
[22]H. Lightman,V. Kosaraju,Y. Burda,H. Edwards,B. Baker,T. Lee,J. Leike,J. Schulman,I. Sutskever,and K. Cobbe。让我们一步一步验证,2023年。
[23] A. Madaan,N. Tandon,P. Gupta,S. Hallinan,L. Gao,S. Wiegreffe,U. Alon,N. Dziri,S. Prabhumoye,Y. Yang,S. Gupta,B. P. Majumder,K. Hermann,S. Welleck,A. Yazdanbakhsh,and P. Clark. 自我完善:自我反馈的迭代完善,2023。
[24] N. McAleese,R. Pokorny,J. F. Cerón Uribe,E. Nitishinskaya,M. Trębacz,and J. Leike。Llm批评者有助于发现llm错误。OpenAI,2024。
[25]OpenAI。Gpt-4技术报告,2024年。
[26] Qin Y., Liang S., Ye Y., Zhu K., Yan L., Lu Y., Lin Y., Cong X., Tang X., Qian B., Zhao S., Hong L., Tian R., Xie R., Zhou J., Gerstein M., Li D., Liu Z., and Sun M. Toolllm: Facilitating Large Language Models to Master 16000+ Real-World APIs, 2023. URL https://arxiv.org/abs/2307.16789.
[27] Qu C., Dai S., Wei X., Cai H., Wang S., Yin D., Xu J. and Wen J-R. Large Language Models for Tool Learning: A Survey, 2024. URL https://arxiv.org/abs/2405.17935.
[28] Y. Qu,T. Zhang,N. Garg,and A. Kumar. 递归自省:教基础模型如何自我改进。2024年。
第 19 页
[29] N. Sardana和J. Frankle。超越chinchilla最优:在语言模型缩放定律中考虑推断,2023年。
[30]W.Saunders,C.Yeh,J.Wu,S.Bills,L.Ouyang,J.Ward,and J.Leike. 自我批评模型以协助人类评估者,2022。
[31]A. Setlur,S. Garg,X. Geng,N. Garg,V. Smith和A. Kumar。RL在错误的合成数据上将LLM数学推理的效率提高了八倍。arXiv预印本arXiv:2406.14532,2024。
[32] Z. Shao,P. Wang,Q. Zhu,R. Xu,J. Song,X. Bi,H. Zhang,M. Zhang,Y. K. Li,Y. Wu,and D. Guo. Deepseekmath:Pushing the limits of mathematical reasoning in open language models,2024。
[33]A.Sharma,S.Keh,E.Mitchell,C.Finn,K.Arora和T.Kollar。对大型语言模型进行对齐的AI反馈的批判性评估,2024年。URL:https://arxiv.org/abs/2402.12366。
[34] N. Shinn,F. Cassano,E. Berman,A. Gopinath,K. Narasimhan,and S. Yao. Reflexion:语言代理与口头强化学习,2023。
[35] A. Singh,J.D.Co-Reyes,R.Agarwal,A.Anand,P.Patil,X.Garcia,P.J.Liu,J.Harrison,J.Lee,K.Xu,A.Parisi,A.Kumar,A.Alemi,A.Rizkowsky,A.Nova,B.Adlam,B.Bohnet,G.Elsayed,H.Sedghi,I.Mordatch,I.Simpson,I.Gur,J.Snoek,J.Pennington,J.Hron,K.Kenealy,K.Swersky,K.Mahajan,L.Culp,L.Xiao,M.L.Bileschi,N.Constant,R.Novak,R.Liu,T.Warkentin,Y.Qian,Y.Bansal,E.Dyer,B.Neyshabur,J.Sohl-Dickstein,和N.Fiedel。超越人类数据:通过语言模型进行问题解决的自我训练扩展,2024年。
[36] C. Snell,E. Wallace,D. Klein和S. Levine。通过微调预测涌现能力。语言建模会议2024,2024年。
[37] K. Stechly,M. Marquez,and S. Kambhampati。GPT-4不知道它错了:对推理问题迭代提示的分析,2023年。
[38] R.S. Sutton和A.G.Barto。强化学习:介绍,第二版,2018年。
[39] G.团队。Gemini 1.5:解锁数百万个上下文中的多模态理解,2024年。
[40]天野,彭博,宋乐,金丽,于德,米海和于德。通过想象、搜索和批评来提高llms的自我改进能力,2024年。
[41] H. Touvron,L. Martin,K. Stone,P. Albert,A. Almahairi,Y. Babaei,N. Bashlykov,S. Batra,P. Bhargava,S. Bhosale,D. Bikel,L. Blecher,C. C. Ferrer,M. Chen,G. Cucurull,D. Esiobu,J. Fernandes,J. Fu,W. Fu,B. Fuller,C. Gao,V. Goswami,N. Goyal,A. Hartshorn,S. Hosseini,R. Hou,H. Inan,M. Kardas,V. Kerkez,M. Khabsa,I. Kloumann,A. Korenev,P. S. Koura,M.-A. Lachaux,T. Lavril,J. Lee,D. Liskovich,Y. Lu,Y. Mao,X. Martinet,T. Mihaylov,P. Mishra,I. Molybog,Y. Nie,A. Poulton,J. Reizenstein,R. Rungta,K. Saladi,A. Schelten,R. Silva,E. M. Smith,R. Subramanian,X. E. Tan,B. Tang,R. Taylor,A. Williams,J. X. Kuan,P. Xu,Z. Yan,I. Zarov,Y. Zhang,A. Fan,M. Kambadur,S. Narang,A. Rodriguez,R. Stojnic,S. Edunov,and T. Scialom. Llama 2: Open foundation and fine-tuned chat models, 2023. URL https://arxiv.org/abs/2307.09288。
[42] J. Uesato,N. Kushman,R. Kumar,F. Song,N. Siegel,L. Wang,A. Creswell,G. Irving,and I. Higgins。基于过程和结果的反馈解决数学文字问题,2022年。
第 20 页
[43] K. Valmeekam,M. Marquez,and S. Kambhampati。大型语言模型真的可以通过自我批评来提高吗?,2023年。
[44]P. Villalobos和D. Atkinson。在训练和推理中权衡计算,2023年。URL:https://epochai.org/blog/trading-off-compute-in-training-and-inference。访问时间:2024-07-03。
[45] Wang Peng, Li Lei, Shao Zheng, Xu Ruixiang, Dai Dong, Li Yan, Chen Ding, Wu Yong, and Sui Zhongsheng. Math-shepherd: Verifying and reinforcing llms one step at a time without human annotations, 2023.
[46] 王瑞,泽利克曼,波西亚,普,哈伯和诺亚·D。戈德曼。假设搜索:语言模型的归纳推理,2024年。URL https://arxiv.org/abs/2309.05660。
[47] Wei J., Wang X., Schuurmans D., Bosma M., Ichter B., Xia F., Chi E., Le Q., Zhou D. Chain-of-thought prompting elicits reasoning in large language models, 2023。
[48] Yao Sheng, Yu Dong, Zhao Jian, Shafran Igor, Griffiths Thomas L., Cao Yan, and Narasimhan Karthik. 思维之树:大型语言模型的有意识问题解决,2023。
[49] Yuan Z., Yuan H., Li C., Dong G., Lu K., Tan C., Zhou C., and Zhou J. Scaling Relationship on Learning Mathematical Reasoning with Large Language Models, 2023。
[50] E. Zelikman,Y. Wu,J. Mu,and N. D. Goodman。Star:通过推理进行推理的自我强化,2022年。
[51] E. Zelikman,G. Harik,Y. Shao,V. Jayasiri,N. Haber和N. D. Goodman。安静的明星:语言模型可以教自己在说话之前思考,2024年。URL https://arxiv.org/abs/2403.09629。
第 21 页
附录
A. 相关工作
语言模型推理。近年来,针对具有挑战性的数学推理任务的语言模型性能迅速提高([20、22、25、32、39])。这些改进可以归因于四个主要因素:1)在大型数学数据集上进行持续预训练;2)通过应用特定推理任务的强化学习来优化LMM建议分布[32、35、49、50],使模型能够迭代地批判和修订其答案[4、8、23、30];3)通过微调验证器使LMM受益于额外的测试时间计算[6、7、10、22、40、42、45、48]。我们的工作建立在这第二和第三条研究线的基础上,分析了如何通过1)细化LMM的建议分布以及2)与验证器进行搜索来改善测试时间计算规模。
分析测试时间计算缩放。Jones [16] 之前研究了使用蒙特卡洛树搜索应用于棋盘游戏Hex的训练时间和测试时间计算之间的权衡。我们相反地将我们的分析集中在全规模语言模型数学推理问题上。Villalobos和Atkinson [44] 的一项调查工作分析了在多个领域中训练与推断之间的权衡,然而他们对语言模型的大部分分析都集中在已知真实答案的测试时间计算缩放设置上。相比之下,我们的分析关注的是当真实答案未知时的情况。此外,在RL文献中有许多作品提出了方法,例如MCTS [19] ,旨在导航测试时间和训练时间计算之间的权衡以实现迭代自我玩乐的形式。我们的工作发现可以用于帮助开发类似算法,这些算法可以在开放自然语言上运行。
在测试时增加计算能力。除了验证器和修订之外,还有许多其他工作提出了使语言模型能够在推理中使用测试时计算的替代方法。例如,Wang等人[46]进行层次假设搜索以实现归纳推理能力。一些相关的工作已经提出在测试时为语言模型添加工具,这可以大大改善它们在下游任务上的性能[11、26、27]。最后,几项工作已经提出了在无监督的情况下学习思想令牌的方法[12、51],从而允许模型更有效地利用采样较长序列带来的额外测试时计算。虽然我们专注于这项工作中通过两种主要机制来扩展测试时计算的能力(例如验证器和修订),但我们执行分析的一些方法(例如根据问题难度确定最佳缩放)也可以应用于这些其他测试时计算缩放方法,并且我们认为这是未来研究的一个有趣方向。
B. 附加修订结果
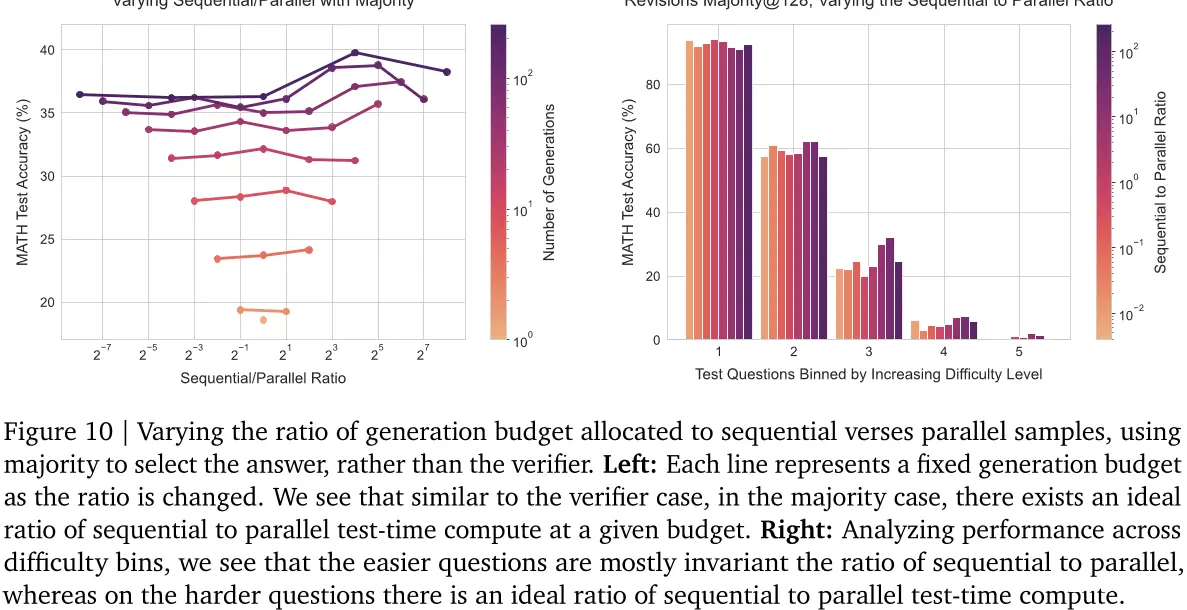
我们在图10中绘制了使用我们的PaLM 2-S*修订模型的多数选择结果。在多数选择的情况下,我们看到的趋势与图7中的验证者选择趋势大致相同。
C. 无监督难度箱
我们通过在每个问题上对2048个样本的PRM最终答案得分进行平均,计算出没有oracle地理解正确性信息的难度桶。这样得到一个与 相应的价值估计值。
第 22 页
问题。然后,我们对测试集中的每个问题的值进行五分位数划分(使用与Oracle难度划分相同的程序)。我们将此称为“预测难度”,而不是“Oracle难度”。技术上,这个过程非常昂贵,因为它需要生成许多样本。虽然我们在分析中没有考虑这种成本,但在实际生产环境中,这将是一个问题。更有效的方法是通过给定的问题直接预测正确性。在我们的工作中,我们没有探索这种方法,但未来的工作可以探索更便宜的方法来估计难度。
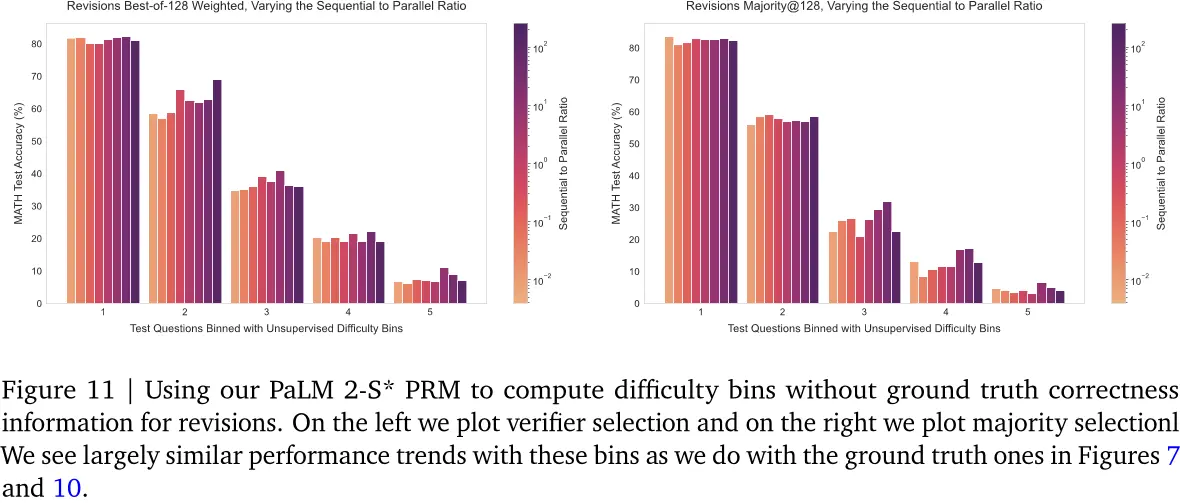
在图12中,我们使用我们的难度分箱绘制PRM搜索结果,在图11中,我们绘制了相应的修订结果。我们看到,在这两种设置下,这些预测的分箱与oracle分箱具有相似的趋势。
D. PRM培训详情
我们将PRM进行二元分类,其中模型在每个解决方案步骤中预测一个介于0和1之间的值。我们使用蒙特卡罗展开获得的软值训练该模型,采用二进制交叉熵损失函数(例如:−(ylog(ˆy)+(1 - y)log(1 - ˆy)), 其中y对应于软真实值,而ˆy为模型预测值)。我们使用AdamW优化器对模型基础模型进行微调,学习率设置为3e-5,批处理大小为128,丢弃率为0.05,并且Adam的贝塔值为(0.9,0.95)。我们进行早期停止,在原始PRM800K训练划分中的随机保留验证集上选择验证损失最低的检查点,该验证集包含原始PRM800K训练划分中问题总数的10%。
我们对每个问题从相应的少量提示基模型中选择16个样本进行微调。在每一步,我们使用相同的基模型和提示,在蒙特卡洛模拟器上运行16次,以估计步骤级价值。我们在训练数据中过滤掉所有无法输出有效、可解析最终答案的样本,因为我们发现这些样本会损害PRM性能。
第 23 页
第 24 页
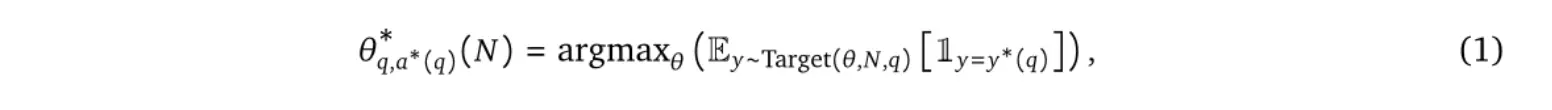
在生成样本时,基础模型被提示以Lightman等人[22]中使用的分步格式输出答案。然后我们使用简单的换行符分割程序将每个答案分为步骤。我们在附录G中包括了关于我们的提示的详细信息。
E. 比较PRM聚合策略
我们比较了不同方法的PRM分数聚合,以产生完整的解决方案的最终得分。具体来说我们比较:1)取所有步骤的最小分值(如Lightman等人所做),例如“min”;2)取所有步骤正确性的概率乘积(例如“prod”);和3)只取最后一步预测(例如“last”。我们在图13中看到,取最后一步比其他两种方法表现更好。先前的工作[22、45]发现min是最佳聚合器。我们认为差异的原因在于我们的验证者被训练使用软MC返回标签,这些标签与二进制正确性标签截然不同,因此其他聚合策略可能没有相同的效果。
有趣的是,当使用最后一步聚合时,我们实际上是在像ORM一样使用PRM。然而,我们看到PRM优于ORM,这表明在我们的案例中,每步的PRM训练可能对表示学习有很大帮助,而不是纯粹作为推理时间的工具。未来的工作应该进一步探索这一思路。
F. 比较PRM和ORM
我们使用PaLM 2-S *基础语言模型训练了PRM和ORM模型。我们在图14中看到,PRM优于ORM,并且随着数量的增加,PRM与ORM之间的差距越来越大。
第 25 页
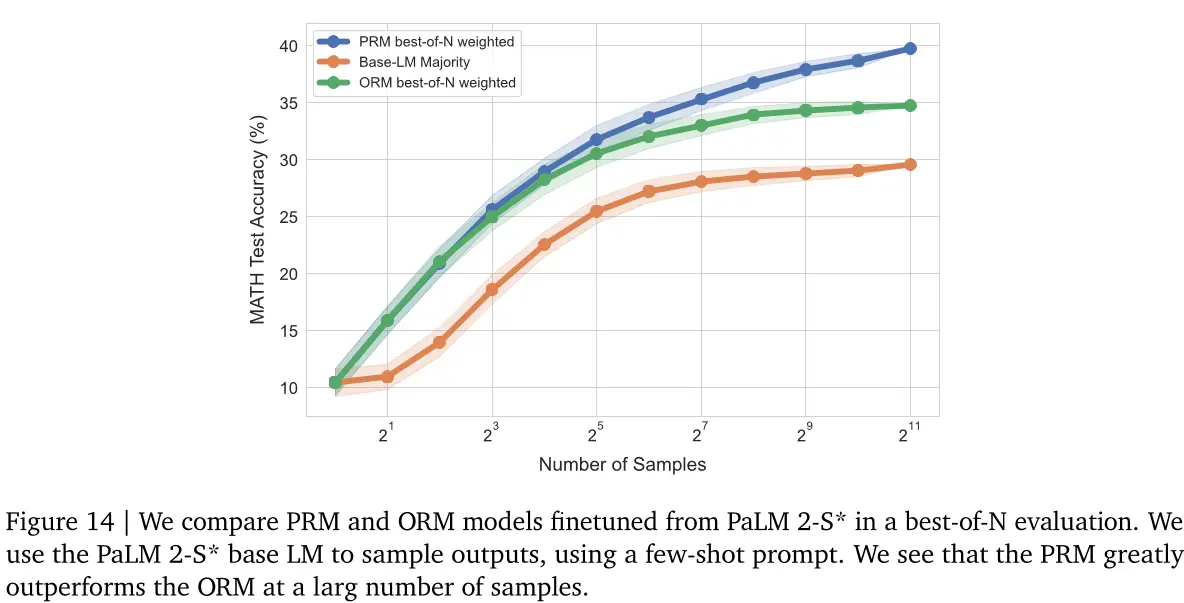
用于样本的使用。我们使用PRM中的最后一步预测来评分答案,如附录E所述。
G. 提示详细信息
为了使基础模型能够以PRM可以应用的分步格式输出答案,我们使用了由Lightman等人[22]发布的LightQA数据集中的随机选择的正确答案示例组成的4个提示。具体来说,我们使用来自第一阶段训练划分的答案。这些答案对应于GPT-4生成的正确答案示例,其中包括正确的分步格式。在初始实验中,我们发现这种提示程序产生的结果与Lewkowycz等人[20]使用的提示类似。我们将此提示用于生成PRM和修订模型的训练数据。我们在测试集中进行搜索时也使用这个提示。为了对通过该提示预测的最终答案进行评分,我们使用了Lightman等人[22]发布的评分函数。
H. 修订模型微调细节
为了对修订模型进行微调,我们遵循第6.1节中概述的程序。首先,对于每个问题,我们采样64个输出。然后,我们将所有以无效解决方案结尾的答案过滤掉。对于每个正确答案,我们再从0到4之间均匀地采样一个数字,表示在训练过程中应包含多少个错误答案作为上下文。正确的答案用于轨迹(我们训练模型生成)中的最后一个答案,并且错误的答案包括在上下文中。如果采样的数字大于0,则根据字符级编辑距离度量找到最近的错误答案并将其包含为轨迹中的最后一个错误答案。这里的目的是选择一个错误
第 26 页
回答,它与正确的答案略有相关性,以改善学习。剩下的错误答案,我们从可用的答案集中随机采样。在少于四个错误的样本被采样的情况下,我们将均匀分布的最大值截断到匹配错误样本的数量。我们使用此程序为训练数据中的所有问题生成轨迹。
然后,我们对这些生成轨迹中的正确答案解决方案进行基语言模型的微调。我们使用AdamW优化器、学习率1e-5、批处理大小128、dropout为0.0和Adam贝塔值(0.9,0.95)。
我们发现,一般在由上述描述生成的轨迹组成的评估集上评估损失,并不能提供一个很好的信号来停止过早。相反,我们发现,在评估损失开始增加之后的检查点更具有可修改性。这很可能是因为在对修订模型进行微调后,评估集代表了离线数据,自然会与模型本身在政策下生成的轨迹不同。因此,我们在观察到验证集上的过拟合时选择我们的修订模型检查点稍晚一些。
I. 修订模型选择标准
如第6.1节所述,为了有效地使用我们的修订模型,我们需要部署一个选择最佳答案的准则,无论是在一个修订轨迹中还是在多个并行轨迹之间。我们采用两种方法:1)ORM验证器;和2)多数投票。
对于ORM验证器,我们根据附录J中的程序训练一个ORM。在推理时,我们使用此验证器选择最佳答案。由于我们有两条轴可以汇总(每个修订轨迹和多个轨迹之间),因此我们部署了一个层次策略,首先在每个修订轨迹中选择最佳答案,然后将这些选定的答案汇总到轨迹上。为了在每个轨迹中选择最佳答案,我们执行最佳的N加权聚合,并且选择具有最大最佳的N加权答案的最佳得分解决方案。然后,在所有修订链上选择最终答案,我们进行另一轮最佳的N加权选择,使用每个修订链的最佳答案。经过第二轮最佳的N加权后,代表我们的最终答案预测。
对于多数投票,我们发现当轨迹长度或轨迹数量太小时,层次聚合会产生问题。问题是,在没有足够样本的情况下,多数投票无法有效地选择最佳选项。因此,对于多数投票,我们简单地将所有答案,跨过所有轨迹,同时取其多数作为最终答案。我们发现这种方法比层次方法产生更平滑的扩展行为。
J.修订模型验证器培训
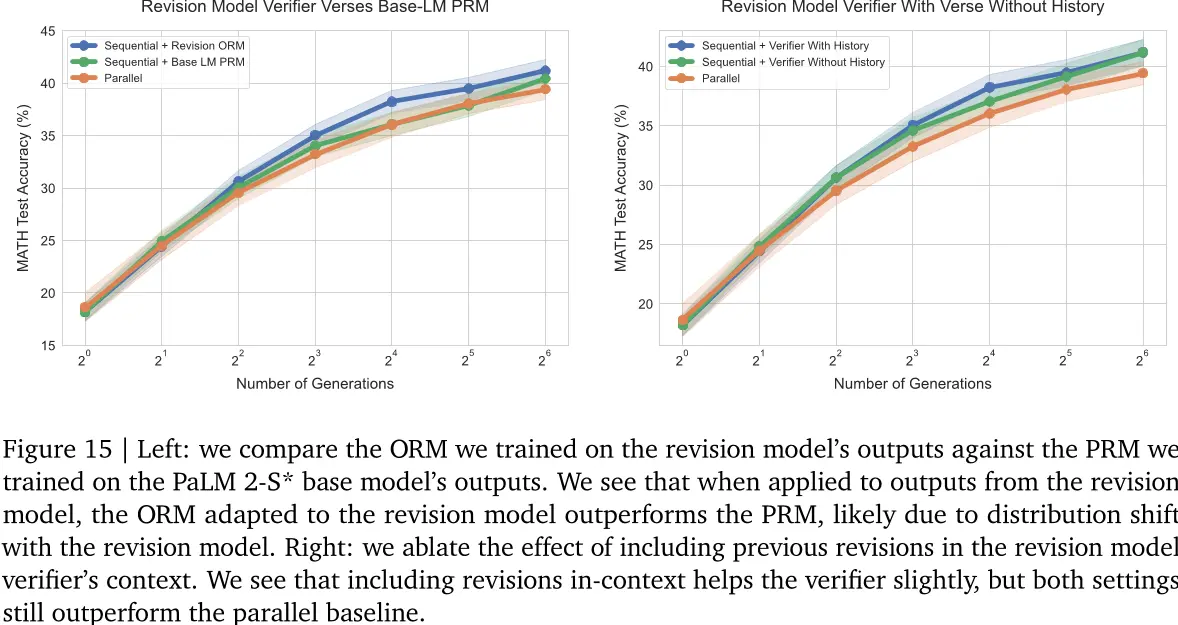
我们发现,我们在PaLM 2-S基础模型上微调的PRM在应用于PaLM 2-S修订模型输出时效果不佳(见图15(a)),这可能是因为与修订模型存在分布偏移。因此,我们训练了一个单独的ORM验证器来使用我们的PaLM 2-S*修订模型。我们也可以训练一个PRM,但由于生成每个步骤的PRM标签成本很高,所以我们选择了ORM。
我们对修订设置的ORM标准进行了微调,通过在上下文中调整ORM以使验证器能够访问与修订模型相同的上下文,从而允许
第 27 页
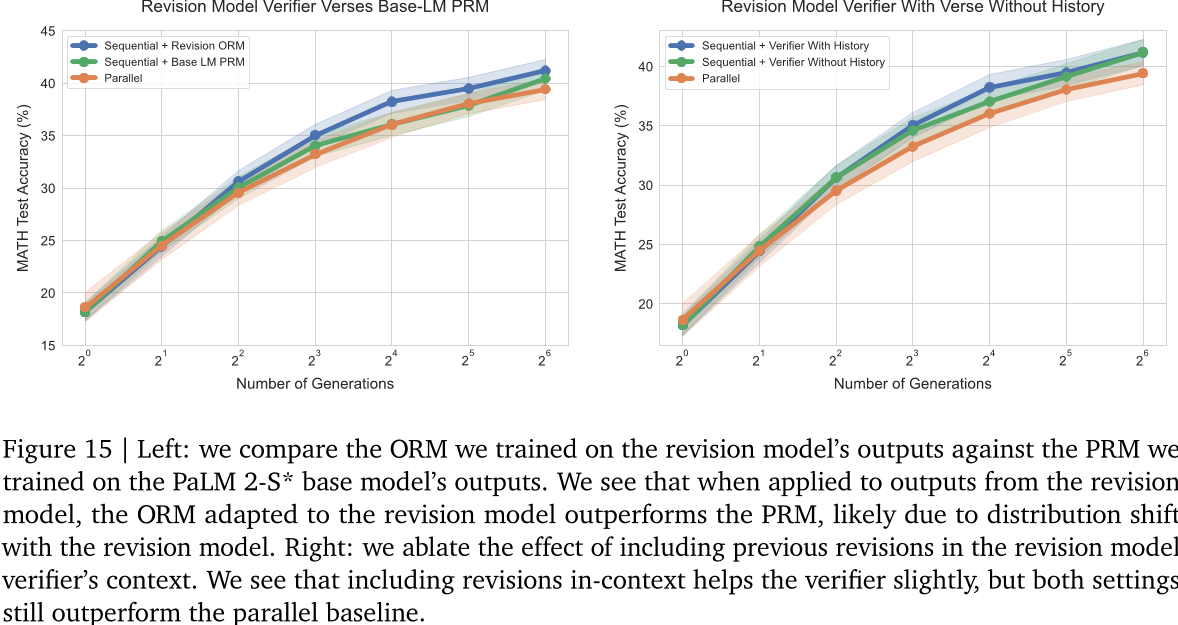
图15 | 左:我们比较了我们在修订模型输出上训练的ORM,与我们在PaLM 2-S*基模型输出上训练的PRM。我们看到,在应用到修订模型的输出时,适应于修订模型的ORM优于PRM,这可能是因为与修订模型存在分布偏移。右:我们消除了将先前修订包含在修订模型验证器上下文中的影响。我们发现,包括修订有助于验证者,但两种设置仍优于平行基准。
当评分当前答案时,验证者可以看到修订模型的先前答案尝试。其他所有实验细节与用于训练PRM时相同。
实验表明,将修订历史包含在上下文中可以略微提高性能(见图15 (b))。此外,在没有上下文的修订的情况下,我们看到顺序修订仍然优于并行修订,这证明了顺序采样改进不仅仅是验证器上下文的结果。
K. ReSTEM修订模型实验
我们通过训练模型使用简化版的RL算法ReSTEM进一步优化了我们的PaLM 2-S*修订模型。具体来说,对于MATH训练集中的每个问题,我们生成了长度为5的最大修订轨迹数为64个。在每条轨迹中,我们停止修订模型的第一个正确答案。然后,我们利用生成的数据对基线语言模型进行微调,并平衡轨迹长度分布以帮助模型学习任务。
在图16中,我们随着序列到并行比率的变化绘制了此新修订模型的性能。我们看到额外的顺序修订对这个新的模型产生了显著的影响。我们假设这种退化是由于运行ReSTEM获得在线数据加剧了修订数据中的虚假相关性,导致优化后的模型无法学习修订任务。我们认为使用更离线的数据收集策略可能更加有效,并将进一步探索留给未来的工作。
第 28 页
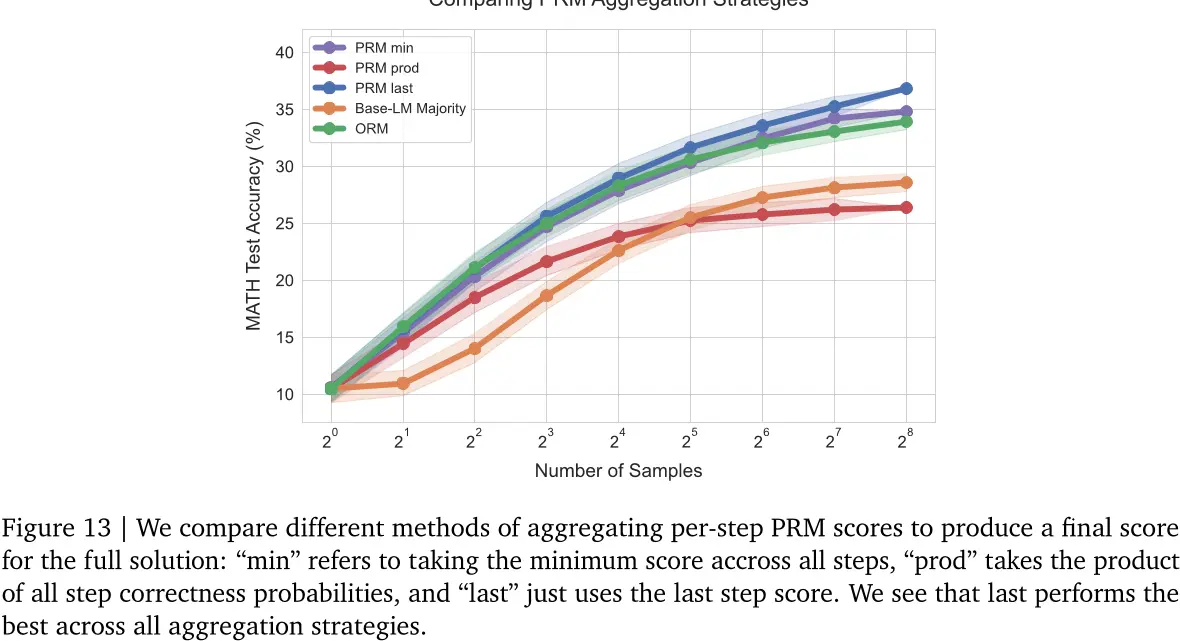
图16 | 随着顺序到并行比率的变化,我们的ReSTEM优化修订模型的性能。我们使用多数投票来选择答案。我们可以看到这个优化修订模型在额外的顺序修订中表现出显著的性能退化。
L. 修订模型示例输出
在图17、18、19、20、21、22和23中,我们包括了我们的修订模型的输出的一些选择性示例。
M. PRM光束搜索示例输出
在图24、25、26、27、28和29中,我们包括了PRM束搜索的几个示例。我们在每个示例中包含PRM得分,范围为0到1。
第 29 页
如果$f(x)=\frac{3x-2}{x-2}$,那么$f(-2)+f(-1)+f(0)$的值是多少?请用最简分数表示你的答案。
尝试1:
让我们来评估$f(-2)$.
我们有$f(-2) = \dfrac{-6 - 2}{-4 - (-4)} = \dfrac{-8}{0} = \infty$.
所以$f(-2)=1$。
让我们来评估$f(-1)$.
我们有$f(-1)=\frac{3(-1)-2}{-1-2}=-\frac{5}{-3}=\frac{5}{3}$.
所以$f(-1)=\frac{5}{3}$.
让我们来评估$f(0)$.
我们有$f(0)=\frac{3(0)-2}{0-2}=\frac{-2}{-2}=1$.
所以$f(0)=1$。
所以我们要计算
$1+\frac{5}{3}+1=\frac{3}{3}+\frac{5}{3}=\frac{3+5}{3}=\frac{8}{3}$。
答案是$\boxed{\frac{8}{3}}$.
8/3
尝试2:
首先让我们找到$f(-2)$.
$f(-2)=\frac{3(-2)-2}{-2-2}=\frac{-6-2}{-4}=\frac{-8}{-4}=2$.
现在让我们找到$f(-1)$.
$f(-1)=\frac{3(-1)-2}{-1-2}=\frac{-3-2}{-3}=\frac{-5}{-3}=\frac{5}{3}$。现在让我们来寻找$f(0)$。
当x=0时,f(0)=3(0)-2/0-2=-2/-2=1。
因此,我们有$f(-2)+f(-1)+f(0)=2+\frac{5}{3}+1= \frac{14}{3}$。
$\frac{7}{3}+\frac{5}{3}+\frac{3}{3}=\frac{7+5+3}{3}=\frac{15}{3}=5$.
答案是$\boxed{5}$.
5
尝试3:
让我们将$x=-2,-1,0$代入$f(x)$.
我们得到$f(-2)=-\frac{8}{-4}=2,f(-1)=\frac{-5}{-3}=\frac{5}{3},f(0)=\frac{-2}{-2}=1$.
所以,我们有$2+\frac{5}{3}+1=\frac{6}{3}+\frac{5}{3}+\frac{3}{3}=\frac{14}{3}$
答案是$\boxed{\frac{14}{3}}$.
14/3
图17 | 修改模型示例1。该模型在前两次尝试中错误地计算了总和,但在第三次尝试中成功并得到正确的答案。
第 30 页
如果皮埃尔、罗莎和托马斯中的任何两个人不能相邻,那么有几种方法可以让 7 个人坐在圆桌周围?(将彼此旋转的座位安排视为相同。)
尝试1:
让我们先来算一下有多少种方法可以安排不能相邻的三个人就座。
所以我们需要让他们坐在三个不是紧挨着的座位上。所以他们可以坐四把椅子。
所以我们有四个空位,需要三个人来填补。
我们可以有四种选择三种方式。
那就是4!/(3!*1!)=4种方式。
现在我们需要找出还有多少种方法可以安排剩下的四个人。所以我们可以把第一个人在七张椅子中的任何一张上坐下。
然后我们可以把第二个人坐在剩下的六个座位中的任何一个。以此类推。
因此,我们可以用七种方式、六种方式、五种方式和四种方式来安排这四个人。
所以我们需要乘上不能坐在一起的三个人的排列方式,以及另外四个人的排列方式。即为:4×7×6×5×4=840。
答案是$\boxed{840}$.
####840
尝试2:
所以我们必须找出有多少种方法可以将7个人安排在一张桌子周围,如果这三个人中的任何两个人不能相邻而坐。
让我们先安排不能坐在一起的三个人。
我们知道他们不能挨着坐,但他们可以坐在桌子的两端。
所以他们可以以三种不同的方式坐着。
现在让我们坐四个人,他们可以坐在任何地方。
我们可以有四种方法来做这件事。
现在让我们安排不能坐在一起的三个人。
让我们把它们放在我们之前发现的三个位置上。
所以有三种不同的方式来安排它们。
所以我们有34!3=3243=216种方法来做这件事。
答案是$\boxed{216}$.
216
尝试3:
所以我们必须找到在圆桌周围安排四个人的方法数。
这样,三个人不能坐在一起。
所以让我们从可以坐在一起的三个人开始。
有三种方法可以安排它们。
现在我们得安排另外四个人。
有四种方法可以做到这一点。
所以,将这七个人安排在桌子周围的所有方法总数是3!×4!=6×24=144。
答案是$\boxed{144}$.
####144
图18 |修订模型示例2。在第一次尝试中,模型采取了错误的方法,在第二次尝试中它更接近但随后在结尾处犯了一个错误。在最后一次尝试中,它到达了正确的答案。
第 31 页
找到$6_8 \cdot 7_8$的乘积。用八进制表示你的答案。52 8
尝试1:
所以我们有 $6 8 \cdot 7_8$.
对。
所以,我们可以将这些数字转换为十进制。
对,我们有$6_8 = 6_10$和$7_8= 7_10$.
因此,我们的方程变为$6_{10}* 7_{10}$。
所以,我们有$6_{10} \times 7_{10}=42_{10}$。
因此,我们需要将十进制数42转换为八进制。
对。
所以,我们知道$4 8=4_{10}$和$2_8=2_{10}$.
所以,我们可以把42除以8得到55余2。
因此,我们的答案是 52。
正确。
52
尝试2:
好吧,我们可以从扩展十进制数开始。
对。所以,$6_8=6$ 和 $7_8=7$.
所以我们得到$6\cdot 7$.
对的,产品是 42 美元。
因此,我们需要将$42$转换为八进制。
对。所以,我们把42除以8,得到余数为2和商为5。
所以,我们写成 528。
正确。
528
图19 | 修改模型示例3。在第一次尝试中,模型对最终答案的格式有错误;它在第二次尝试中纠正了这个问题。
第 32 页
找到$6_8 \cdot 7_8$的乘积。用八进制表示你的答案。52 8
尝试1:
让我们把它们相乘。
我们得到$6_8 \cdot 7_8 = 42_8$.
答案是 42。
42_8
尝试2:
我们知道$6_8=6,7_8=7$,所以问题是找到$6\cdot 7$.对的。
66.7=42。
正确。这意味着$6_8 \cdot 7_8 = 42_8$.
因此,我们的答案是 42。
42_8
尝试3:
让我们在八进制下乘以 6 和 7。
在十进制中,$6 \cdot 7=42$.
是的。所以,$6_8 \cdot 7_8 = 42_{10} = 40_8 + 2_8$.
我们可以把它重写为:$40_8 +2_8 = 40_8+10_8+ 10_8+8_8+8_8+8_8+8_8+8_8+1_8$.
我们可以把它重写为 $40_8 + 10_8 +10_8+10_8 + 10_8 + 10_8+ 10_8 + 10_8+1_8$.
我们可以把它重写为 50_8 + 1_8。
所以,$6_8 \cdot 7_8=51_8$.
51
尝试4:
因此,$6_8 \cdot 7_8$ 在八进制中是$6 \cdot 7$.
对的。
让我们将$6$和$7$转换为十进制。$6 =6_8= 6 \cdot 8^0 + 0 \cdot 8^1 = 6$.
对。并且,7=7_8=7·8^0+0)·8^1=7。
对。所以,6×7=6×7=42。
八进制中的 42 是 52。
那是正确的。
####52 8
图20 |修订模型示例4。在最初的几次尝试中,该模型未能将十进制转换为八进制。在最后一次尝试中,它进行了正确的计算。
第 33 页
将直角坐标系中的点(0,3)转换为极坐标。以形式(r,θ)输入答案,其中r大于零且0≤θ<2π。
尝试1:
要将$(0,, 3)$转换为极坐标,我们需要找到半径$r$和角度$\theta$.
我们知道点的$x$坐标为$r \cos \theta$,而
点的$y$坐标为$r \sin \theta$.
所以$r \cos \theta=o$,而$r \sin \theta=3$.
我们知道当$\theta=\frac{\pi}{2}$时,$\cos\theta=0$;当$\theta=\frac{3\pi}{2}$时,$\sin\theta=3$.
因此我们知道,$(0, 3)$对应于$\theta=\frac{3\pi}{2}$和$r\cos\theta=0$以及$r\sin\theta=3$的点。
所以$r=\frac{3}{\sinθ}=\frac{3}{\sin(\frac{3π}{2})}=
$\frac{3}{\frac{3}{2}}=2$.
因此,极坐标为(0,3)的点是(2,π/2)。
(2, 3π/2)
尝试2:
要将直角坐标系中的点(0,3)转换为极坐标系,我们需要找到使极坐标(r,θ)等于直角坐标(x,y)的等价角度θ。
我们知道$(r,\theta)=(0,3)$和$(x,y)=(0,3)$.
所以让我们建立一个方程,其中$r$等于$x$和$\theta$等于$y$.
我们有$r=x$和$y=\theta$。
因此我们可以将这些代入极坐标方程$r=\sqrt{x^{2}+y^{2}}$。我们得到$\sqrt{x^{2}+y^{2}}=X$。
我们可以将等式两边平方,得到$x^2+y^2=x^2$。
我们可以在等式的两边减去$x^2$,得到$y^2=0$.
我们知道,要满足$y^2= 0$,我们必须有$y =0$.
因此,使极坐标$(r,\theta)$等于直角坐标$(x,y)$的角$\theta$是$\theta=0$.
半径$r$等于$x$坐标,即$x=r=0$。
因此,极坐标与$(0, 3)$等价的是$(r, \theta)=(0, 0)$.是。
我们还知道$r>0$和$o \le \theta < 2\pi$.
因此,极坐标与$(0, 3)$等价的是$(r,\theta)=(0,0)$. #### (0,0)
尝试3:
要将直角坐标系中的点(0,3)转换为极坐标,我们需要找到半径$r$和角度$\theta$.
点的$x$坐标为0,所以$x=r \cos \theta=0$。
我们知道当$\theta=\frac{\pi}{2}$或$\theta=\frac{5\pi}{2}$时,$\cos\theta=0$.
因此我们可以使用$\theta=\frac{\pi}{2}$或$\theta=\frac{5\pi}{2}$.
点的纵坐标为3,所以$y=r \sin \theta=3$.
我们知道$\sinθ=\frac{3}{f r}$.
我们可以使用方程$\sinθ=\frac{3}{r}$来找到$r$.
我们知道$\sin\frac{\pi}{2}= 1$,所以$r=\frac{3}{1}=3$.
因此,我们的极坐标是$(3,\frac{\pi}{2})$或$(3,B, \frac{5\pi}{2})$。
并且由于$O0\lee\theta < 2 \pi$,我们有$\theta=\frac{\pi}{2}$.
因此,我们的极坐标是$(3, \frac{\pi}{2})$。
####(3,\frac{\pi}{2})
图21 |修订模型示例5。在前两次尝试中,该模型将欧几里得坐标转换为极坐标时出错。在最后一次尝试中,它没有犯这些错误。
第 34 页
12的适当因子是1,2,3,4和6。一个整数N的适当因子是一个正因子小于N。那么284的适当因子之和是多少?
尝试1:
好的,我们先找284的正约数。
对。所以,284的正约数是1、2、4、71和142。
所以,284的正约数之和是1+2+4+71+142,即为219。
现在让我们找到219的适当因子。
219的正约数是1,3,73和219。
所以,219的正约数之和是1+3+73+219,即306。
所以问题的答案是306。
####306
尝试2:
因此,284的适当因子之和为1+2+4+71+142。
好的。
284的适当因子是1,2,4,71和142。
对。
它的全部真因数之和是219。
所以,284的正约数之和为219。
对。
因此,284的正约数之和是219的正约数之和。
对。
219的适当因子是1,3,73和219。
对。
所以,219的正约数之和为:1+3+73+219=306。
因此,284的正约数之和的正约数之和为306。
对。
所以问题的答案是306。
####306
尝试3:
好的,所以284的正约数是1、2、4、71和142。
所以,284的正约数之和是1+2+4+71+142,即为220。
现在让我们找到220的适当因子。
220的适当因子是1,2,4,5,10,11,20,22,44,55和110。
所以,220的正约数之和是1+2+4+5+10+11+20+22+44+55+110,即为284。
所以问题的答案是284。
####284
图22 |修订模型示例6。在前两次尝试中,该模型在求解284的适当因子之和时出错。第三次尝试正确地评估了这个和。
第 35 页
如果-6≤a≤-2和3≤b≤5,那么最大可能值是多少?
将以下英文文本翻译成中文。 $ \displaystyle\left(a+\frac{1}b}\right)\left(\frac{1}{b}-alright) $? 将您的答案表示为最简分数形式。
尝试26:
所以我们有 $-6 \leg a\leg -2$ 和 $3 \leq b \leg 5$。
我们想找到最大可能的值
$\displaystyle \left(a+\frac{1}{b}\right)\left(\frac{1}{b}-a\right)$.
所以我们想找到最大可能的值
$\displaystyle\left(a+\frac{1}{b}\right)\left(\frac{1}{b}-a\right)$,其中$-6
$\leq a \leq -2$ 和 $3 \leq b \leq 5$。
好的,让我们先找到$a$的最大可能值和最小
可能的$b$值。
好的,那么$a$的最大可能值是-2。
而$b$的最小可能值是$3$.
所以我们想找到最大可能的值
$\displaystyle\left(a+\frac{1}{b}\right)\left(\frac{1}{b}-a\right)$,其中$a=-2$和$b=3$.
所以我们想找到最大可能的值
$\displaystyle\left(-2+\frac{1}{3}\right)\left(\frac{1}{3}-(-2)\right)$.
所以我们想找到最大可能的值
$\displaystyle \left(-2+\frac{1}{3}\right)\left(\frac{1}{3}+2\right)$.
所以我们想找到最大可能的值
$\displaystyle \left(-2+\frac{1}{3}\right) \times \frac{5}{3}$。
所以我们想找到最大可能的值
$\displaystyle\left(\frac{-6+1}{3}\right)\left(\frac{5}{3}\right)$.
所以我们想找到最大可能的值
$\displaystyle\left(-\frac{5}{3}\right)\left(\frac{5}{3}\right)$.
所以我们想找到$\displaystyle\frac{-5}{3} \cdot\frac{5}{3}$的最大可能值。
所以我们想找到-25/9的最大值。所以最大可能的值是
$\displaystyle\left(a+\frac{1}{b}\right)\left(\frac{1}{b}-a\right)$,其中$-6
当$a \leq -2$且$3 \leq b \leq 5$时,$\boxed{\frac{-25}{9}}$。 #### \frac{-25}{9}
尝试27:
好的,所以我们要找到最大可能值
$\displaystyle \left(a+\frac{1}{b}\right)\left(\frac{1}{b}-a\right)$.
所以我们想找到最大可能的值
$\displaystyle\left(a+\frac{1}{b}\right)\left(\frac{1}{b}-a\right)$,其中$-6\leq a \leq -2$和$3 \leq b \leq 5$。
好的,那么让我们先找到$a$的最大可能值和$b$的最小可能值。
好的,那么$a$的最大可能值是-2。
并且$b$的最小可能值是$3$.
所以我们想找到最大可能的值
$\displaystyle\left(a+\frac{1}{b}\right)\left(\frac{1}{b}-a\right)$,其中$a=-2$和$b=3$.
所以我们想找到最大可能的值
$\displaystyle\left(-2+\frac{1}{3}\right)\left(\frac{1}{3}-(-2)\right)$.
所以我们想找到最大可能的值
$\displaystyle \left(-2+\frac{1}{3}\right)\left(\frac{1}{3}+2\right)$.
所以我们想找到最大可能的值
$\displaystyle \left(-\frac{5}{3}\right) \left(\frac{7}{3}\right)$。
所以我们想找到$\displaystyle -\frac{5}{3} \cdot \frac{7}{3}$的最大可能值。
所以$\displaystyle -\frac{5}{3}\cdot \frac{7}{3}=\frac{-35}{9}$。
所以最大可能的值是
$\displaystyle\left(a+\frac{1}{b}\right)\left(\frac{1}{b}-a\right)$,其中$-6\leq a \leq -2$和$3 \leq b \leq 5$是$\boxed{\frac{-35}{9}}$。
-\frac{35}{9}
图23 |修订模型示例7。在第一次尝试中,该模型将13 + 2错误地评估为15。在第二次尝试中,它纠正了这个错误。
第 36 页
无穷等比数列$\left{\frac{1}{4},\frac{1}8},\frac{1}16},Idots \right}$的前$n$项和为$\frac{255}{512}$.求$n$.
序列的前 n 项之和只是$\frac{a}{1-r}s,其中 a 是序列的第一个项, r 是公比。[得分 = 0.085] 如果我们把这个特定序列的前 n 项之和等于$\frac{255}{512}$,我们会得到$n=\boxed{7}。[得分 = 0.11] 实际上,在S\frac{255}{512} 的十进制展开中没有出现 7。[得分 = 0.10] 对,所以我们可以把$\frac{\frac{1}{4}(1-\frac{1}{2^n})}{1-\frac{1}{2}}= \frac{255}{512}$,并求解$n。[得分 = 0.10] 所以我们得到$n=7。[得分 = 0.10]
这给$1-{\left(\frac{1}{2}\right)}^{n}=\frac{255}{256}$。[得分= 0.15]
因此,$1-(\frac{1}{2})^n=(\frac{1}{2})^8$。[得分=0.15]
7「得分=0.301
图24 | PRM光束搜索示例1。
无限等比数列S({1/4}, 1/8, 1/16,…)的前n项之和是$\frac{255}{512}$S。求$n$.
由于每个项的公比为S\frac{1}{2}s,因此此等比数列前Sn$项之和是$\frac{a_1(1-r^n)}{1-r}$,其中$a_i$是第一项。
srs是共同比率。[得分=0.09]
因此,这个几何序列的前Sns项之和是S\frac{\frac{1}{4}\left(1-\left(\frac{1}{2}\right)An\right)}{1-\frac{1}{2}}。
因此,这个几何序列的前 n 项之和是 S\frac{\frac{1}{4}\left(1-\left(\frac{1}{2}\right)An\right)}{\frac{1}{2}}。[得分=0.11]
对。我们想要$s_n=\frac{255}{512}$,所以有$\frac{1-{\left(\frac{1}{2}\right)}^{n}}{2}=\frac{255}{512}$。[得分=0.14]
我们可以将两边都乘以2。[得分=0.1]
我们有$1-{\left(\frac{1}{2}\right)}^{n}=\frac{255}{256}$。[得分=0.14]
因此,$(\frac{1}{2})^n= 1 -\frac{255}{256}$。[得分:0.16]
因此,$(\frac{1}{2})^n=\frac{1}{256}$。[得分=0.30]
然后,$2^{-n}= 2^{-8}$。[得分= 0.80]
所以$-n=-8$。[得分:0.78]
对。因为底数相同,所以指数必须相等。[得分= 0.83]
8 [分数= 0.69]
图25 | PRM光束搜索示例2。
将以下英文文本翻译成中文。
我们知道$a^{2}+2ab+b^{2}=(a+b)^{2}$。[得分:0.33]
因此$441+2 \cdot 21 \cdot 19+361=(21+19)^{2}$. [得分= 0.49]
因此我们得到$(21+19)^2=x$。[得分= 0.56]
因此我们得到$x=40^2=1600$。
因此,我们得到$x=1600S.[分数= 8.94]
我们都知道$x=1600S$。[得分= 0.951
那就是我们的答案。[得分= 0.93]
因此$441+2(21)(19)+361=1600$. [得分:0.93]
所以$x=1600$。「分数为8.931」
Right. So $441+2(21)(19)+361=1600$. [score = 0.94]one
1600 [分数= 0.91]
图26 | PRM光束搜索示例3。
确定直线Sy=-x+6上的点P的坐标,使得点P到点A(10,-10)和点O(0,0)的距离相等(即满足PA=PO),并用有序对(a,b)表示你的答案。
所以我们被给予的线是Sy=-x+6s,我们需要找到那条线上的一点,使得从该点到坐标为(-10, 10)的点的线段长度相同。
从点到原点的线段。[得分= 0.01]
对。一种方法是使用距离公式。让我们找到P和(10,-10)之间的距离以及P和原点之间的距离。[得分= 0.01]
对。所以P和(10,-10)之间的距离是$\sqrt{(x_P-10)^2+(y_P+10)^2}$的平方根。同样地,P和原点之间的距离是$\sqrt{ }$ 的平方根。
$(x_P)^2+(y_P)^2$。[得分=0.01]
因此这两个距离必须相等。所以$(x_P-10)^2+(y_P+10)^2=(x_P)^2+(y_P)^2$。展开左侧得到$x_P^2-20x_P+100+y_PA2+20y_P+100=x_P^2+y_PA2$。[得分:0.02]现在我们可以从两边减去$x_P^2$,得到$-20x_P+20y_P+200=0$。[得分:0.02]
但是我们知道$y_P=-X_P+6$,所以我们可以将这个值代入,得到$-20x_P+20(-X_P+6)+200=0$。
然后我们就可以分配20,得到$-20x_P-20x_P+120+200=0$。现在我们可以合并项,得到$-40x_P+320=0$。然后我们可以在两边减去320,得到$-40x_P=-320$。在两边除以-40,得到$x_P=8$。[得分:0.12]
我们知道,$y_P=-x_P+6$ 和 $x_P=8s$, 所以如果我们用$8$代替$xP$我们得到$y_P=-8+6$. [得分:0.22]
对。将$x_p$和$y_P$的值代入方程Sy=-x+6s,我们得到Sy=-8+6,简化为$y=-2$。所以点$(8,-2)$与给定的点等距。正确。
####(8,-2)[分数= 0.39]
图27 | PRM光束搜索示例4。
第 37 页
确定直线Sy=-x+6上的点P的坐标,使得点P到点A(10,-10)和点O(0,0)的距离相等(即满足PA=PO),并用有序对(a,b)表示你的答案。
所以我们被给予的线是Sy=-x+6,我们需要找到那条线上的一点,使得从该点到坐标为(10,-10)的点的线段长度相同。
从点到原点的线段。[得分= 0.01]
好的,那么一种方法是使用距离公式。让我们找到P和(10,-10)之间的距离以及P和原点之间的距离。
对。所以P和(10,-10)之间的距离将是$\sqrt{(x_P-10)^2+(y_P+10)^2}$的平方根。同样地,P和原点之间的距离将是$\sqrt{(x_P)^2+(y_P)^2}$的平方根。[得分=0.01]
因此这两个距离必须相等。所以$(x_P-10)^2+(y_P+10)^2=(X_P)^2+(y_P)^2$。展开左侧得到$x_P^2-20x_P+100+y_PA2+20y_P+100=x_P^2+y_PA2$。[得分:0.02]现在我们可以从两边减去$x_PA2$,得到$-20x_P+20y_P+200=0$。[得分:0.02]
但是我们知道$y_P=-x_P+6$,所以我们可以将这个值代入,得到$-20x_P+20(-X_P+6)+200=0$。
然后我们就可以分配20,得到$-20x_P-20x_P+120+200=0$。现在我们可以合并项,得到$-40x_P+320=0$。然后我们可以在两边减去320,得到
$-40x_P=-320$,将等式两边除以-40,得到$x_P=8$。[得分:0.12]
因此,我们现在知道$x_P=8$。然后我们可以将这个值代入方程$y_P=-x_P+6$来找到$y_P$。这使得$y_P=-8+6$简化为$y_P=-2$。[得分=0.30
3,3 [分数= 0.12]
如果4个daps等于7个yaps,而5个yaps等于3个baps,那么多少个daps等于42个baps?
所以4个daps等于7个yaps,这意味着一个dap等于7/4个yaps或1.75个yaps。[得分=0.21]而5个yaps等于3个baps,这意味着一个yap等于3/5个baps或0.6个baps。[得分=0.32我们可以通过这些值来找到答案。[得分=0.31]所以42个baps等于42/0.6个yaps或70个yaps。[得分=0.60]而70个yaps等于70/1.75个daps或40个daps。[得分=0.87]因此答案是S\boxed{40} s。[得分=9.92]并且我们完成了![得分=8.91]这就是我们的最终答案。[得分=0.90][得分=0.91]所以40个daps等于42个baps。[得分=0.90]并且我们完成了![得分=0.91这是我们的最终答案。[得分=0.90][得分=0.641[得分=0.781#### 40 [得分=0.831
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。